
Sophisticated Web Scraping with Bright Data


Key Takeaways
- Bright Data provides services to make web scraping easier, reliable, and practical. It offers solutions to overcome barriers that websites place to prevent scraping, such as checking the user agent, requiring user interaction, and blocking repeated requests from the same IP address.
- Bright Data datasets are an easy way to start, especially when requiring data from ecommerce platforms, social media platforms, business sites, and directories. These datasets are priced according to complexity, analysis, and the number of records.
- Bright Data’s Web Scraper IDE allows for the scraping of custom data from any website using a collector, a JavaScript program which controls a web browser on Bright Data’s network. It provides API commands for various actions such as navigating to a URL, waiting for requests to finish, clicking a specific element, and solving CAPTCHAs.
- Bright Data’s proxy network offers various proxies, including residential, ISP, datacenter, mobile, and more. These can be used for testing apps on specific networks or downloading data as if it’s a user in a different location. The proxy use can become complex, so Bright Data suggests contacting an account manager to discuss requirements.
It’s easy to make requests for structured data served by REST or GraphQL APIs. Scraping arbitrary data from any web page is more of a chore, but it opens further opportunities. Bright Data provides services to make scraping easier, reliable, and practical.
We created this article in partnership with Bright Data. Thank you for supporting the partners who make SitePoint possible.
Scraping data is web developer super power that puts you above the capabilities of ordinary web users. Do you want to find the cheapest flight, the most discounted hotel room, or the last remaining next generation games console? Mortal users must manually search at regular intervals, and they need a heavy dose of luck to bag a bargain. But web scraping allows you to automate the process. A bot can scrape data every few seconds, alert you when thresholds are exceeded, and even auto-buy a product in your name.
For a quick example, the following bash command uses Curl to fetch the HTML content returned by the SitePoint blog index page. It pipes the result through Grep to return links to the most recent articles:
curl 'https://www.sitepoint.com/blog/' | \
grep -o '<article[^>]*>\s*<a href="[^"]*"'
A program could run a similar process every day, compare with previous results, and alert you when SitePoint publishes a new article.
Before you jump in and attempt to scrape content from all your favorite sites, try using curl with a Google search or Amazon link. The chances are you’ll receive an HTTP 503 Service Unavailable with a short HTML error response. Sites often place barriers to prevent scraping, such as:
- checking the user agent, cookies, and other HTTP headers to ensure a request originates from a user’s browser and not a bot
- generating content using JavaScript-powered Ajax requests so the HTML has little information
- requiring the user to interact with the page before displaying content — such as scrolling down
- requiring a user to log in before showing content — such as most social media sites
You can fix most issues using a headless browser — a real browser installation that you control using a driver to emulate user interactions such as opening a tab, loading a page, scrolling down, clicking a button, and so on.
Your code will become more complex, but that’s not the end of your problems. Some sites:
- are only available on certain connections, such as a mobile network
- limit content to specific countries by checking the requester’s IP address (for example, bbc.co.uk is available to UK visitors but will redirect those from other countries to bbc.com which has less content and advertisements)
- block repeated requests from the same IP address
- use CAPTCHAs or similar techniques to identify bots
- use services such as Cloudflare, which can prevent bots detected on one site infiltrating another
You’ll now need proxy servers for appropriate countries and networks, ideally with a pool of IP addresses to evade detection. We’re a long way from the simplicity of curl combined with a regular expression or two.
Fortunately, Bright Data provides a solution for these technical issues, and it promises to “convert websites into structured data”. Bright Data offers reliable scraping options over robust network connections, which you can configure in minutes.
No-code Bright Data Datasets
Bright Data datasets are the easiest way to get started if you require data from:
- ecommerce platforms such as Walmart and various Amazon sites (
.com,.de,.es,.fr,.it,.inor.co.uk) - social media platforms including Instagram, LinkedIn, Twitter, and TikTok
- business sites including LinkedIn, Crunchbase, Stack Overflow, Indeed, and Glassdoor
- directories such as Google Maps Business
- other sites such as IMDB
Typical uses of a dataset are:
- monitoring of competitor pricing
- tracking your best-selling products
- investment opportunities
- competitive intelligence
- analyzing customer feedback
- protecting your brands
In most cases, you’ll want to import the data into databases or spreadsheets to perform your own analysis.
Datasets are priced according to complexity, analysis, and the number of records. A site such as Amazon.com provides millions of products, so grabbing all records is expensive. However, you’re unlikely to require everything. You can filter datasets using custom subsets to return records of interest. The following example searches for SitePoint book titles using the string Novice to Ninja. This returns far fewer records, so it’s available for a few pennies.
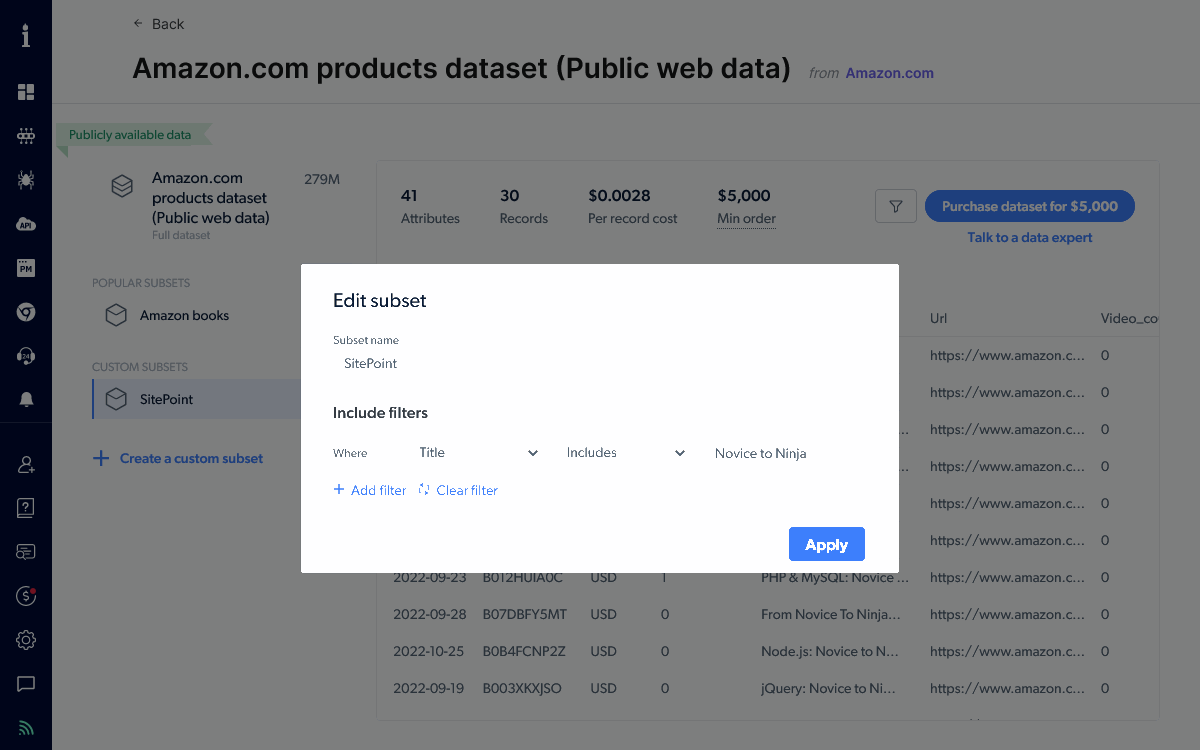
You can receive the resulting data by email, webhook, Amazon S3, Google Cloud Storage, Microsoft Azure Storage, and SFTP either on a one-off or timed basis.
Custom Datasets and the Web Scraper IDE
You can scrape custom data from any website using a collector — a JavaScript program which controls a web browser on Bright Data’s network.
The demonstration below illustrates how to search Twitter for the #sitepoint hashtag and return a list of tweets and metadata in JSON format. This collector will be started using an API call, so you first need to head to your account settings and create a new API token.
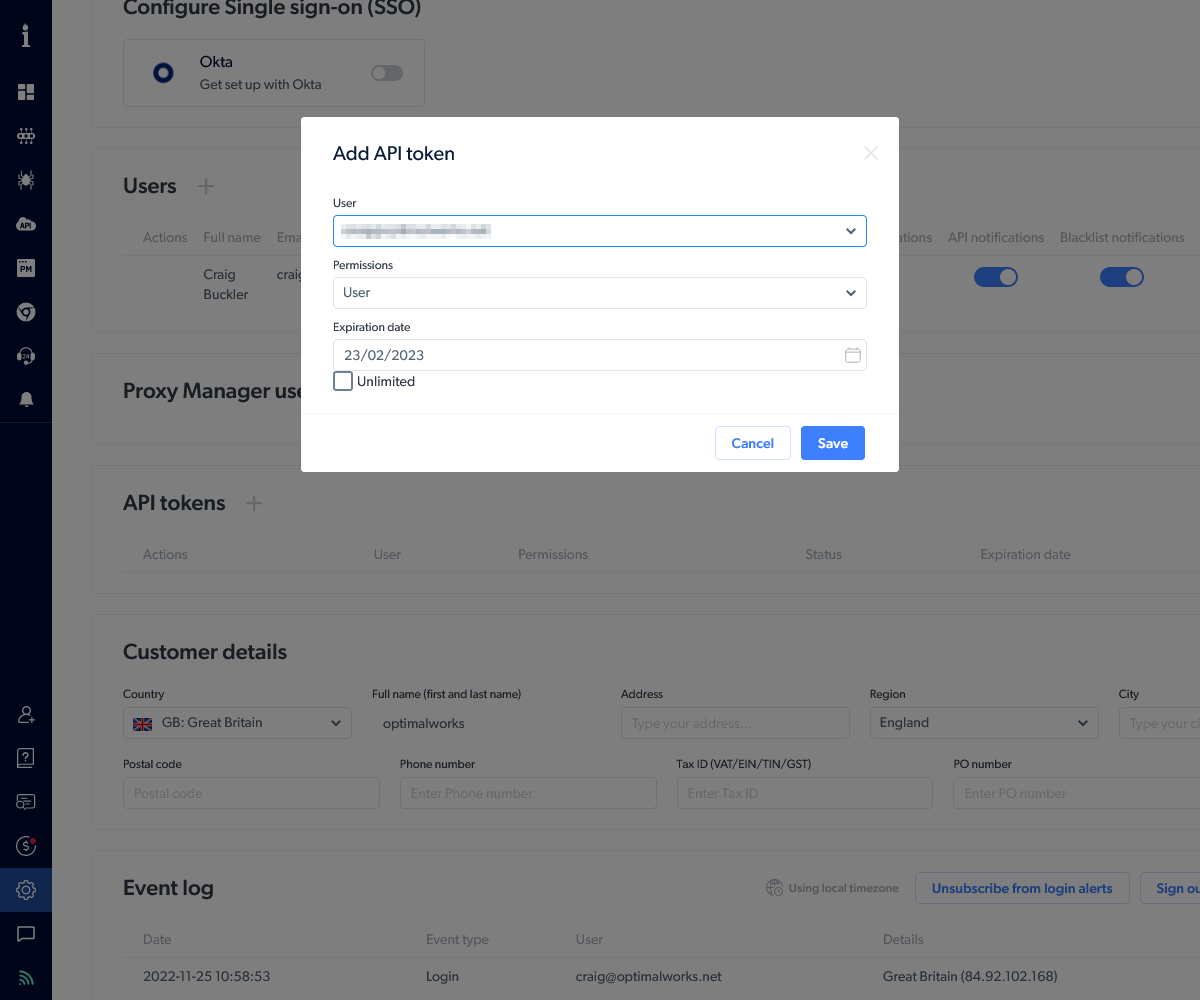
Bright Data will send you an email with a confirmation number. Enter it into the panel and you’ll see your token (a 36-character hex GUID). Copy it and ensure you’ve stored it safely: you won’t see it again and will need to generate a new token if you lose it.
Head to the Collectors panel in the Data collection platform menu and choose a template. We’re using Twitter in this example but you can select any you require or create a custom collector from scratch:
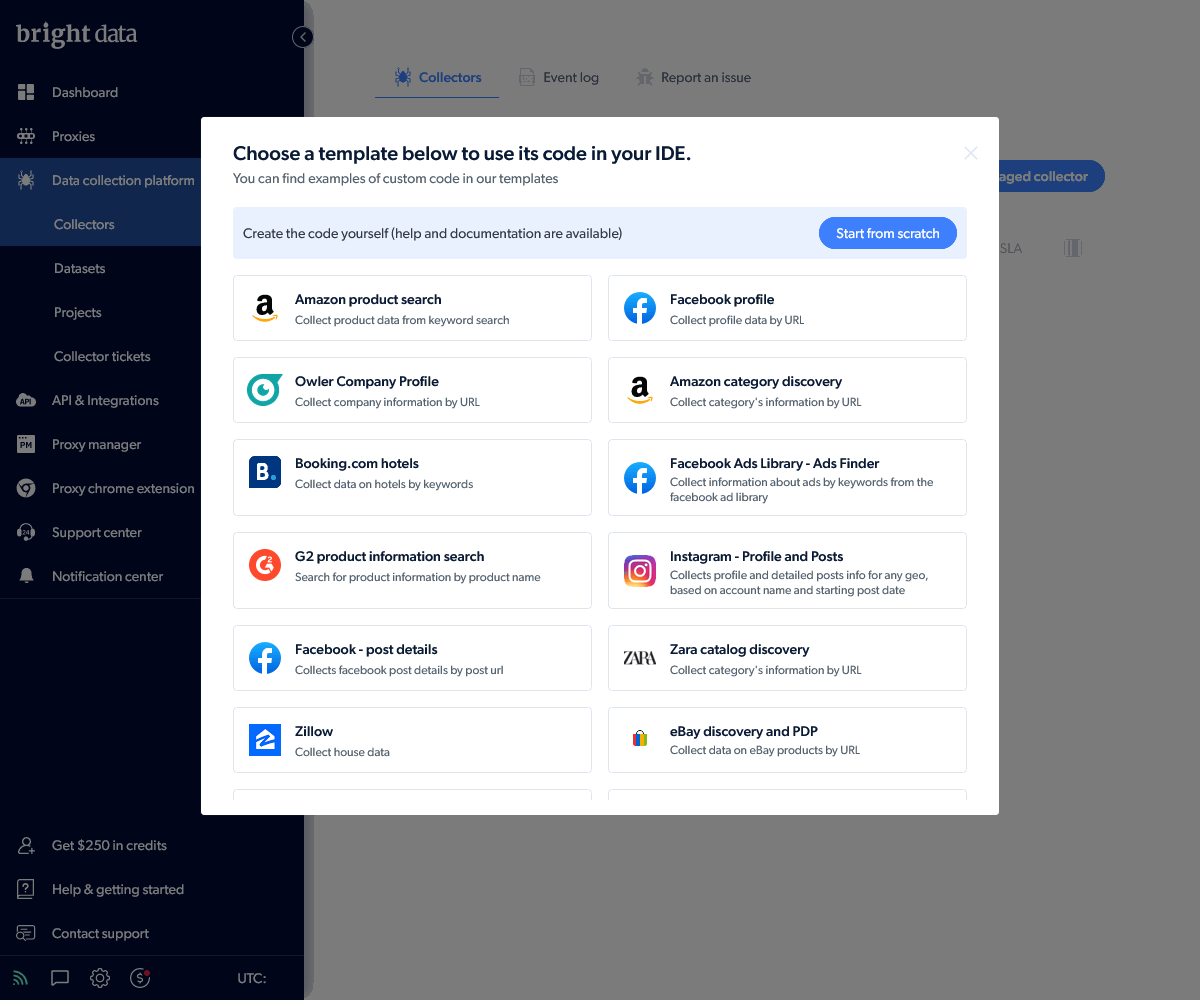
This leads to the Web Scraper IDE where you can view and edit the collector JavaScript code. Bright Data provides API commands such as:
country(code)to use a device in a specific countryemulate_device(device)to emulate a specific phone or tabletnavigate(url)to open a URL in the headless browserwait_network_idle()to wait for outstanding requests to finishwait_page_idle()to wait until no further DOM requests are being madeclick(selector)to click a specific elementtype(selector, text)to enter text into an input fieldscroll_to(selector)to scroll to an element so it’s visiblesolve_captcha()to solve any CAPTCHAs displayedparse()to parse the page datacollect()to add data to the dataset
A help panel is available, although the code will be familiar if you’ve programmed a headless browser or written integration tests.
In this case, the Twitter template code needs no further editing.
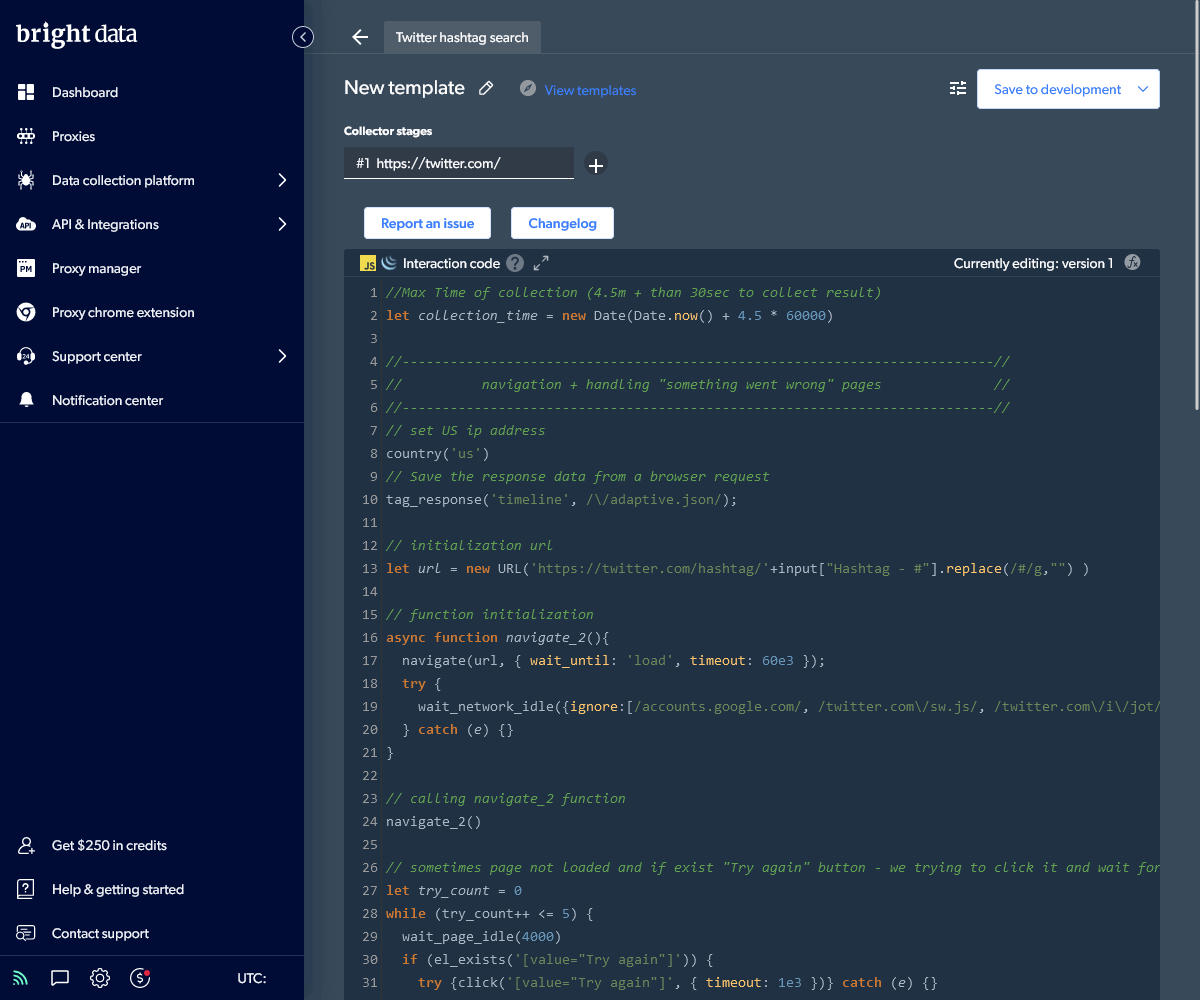
Scroll to the bottom and click the Input panel to delete example hashtags and define your own (such as #SitePoint). Now click the Preview button to watch the code execute in a browser. It will take a minute or two to fully load Twitter and scroll down the page to render a selection of results.
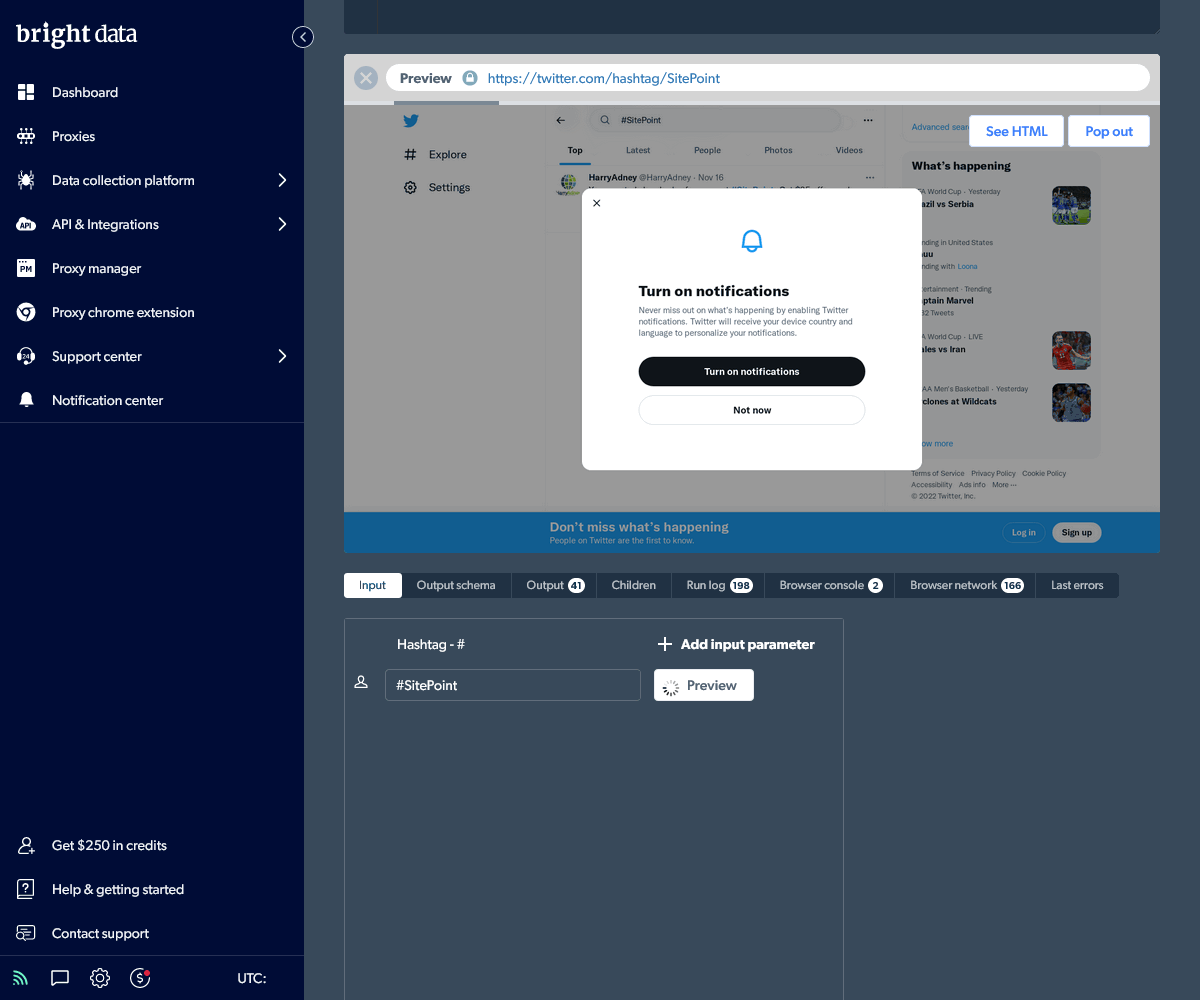
The Output panel displays the captured and formatted results once execution is complete. You can download the data as well as examine the run log, browser console, network requests, and errors.
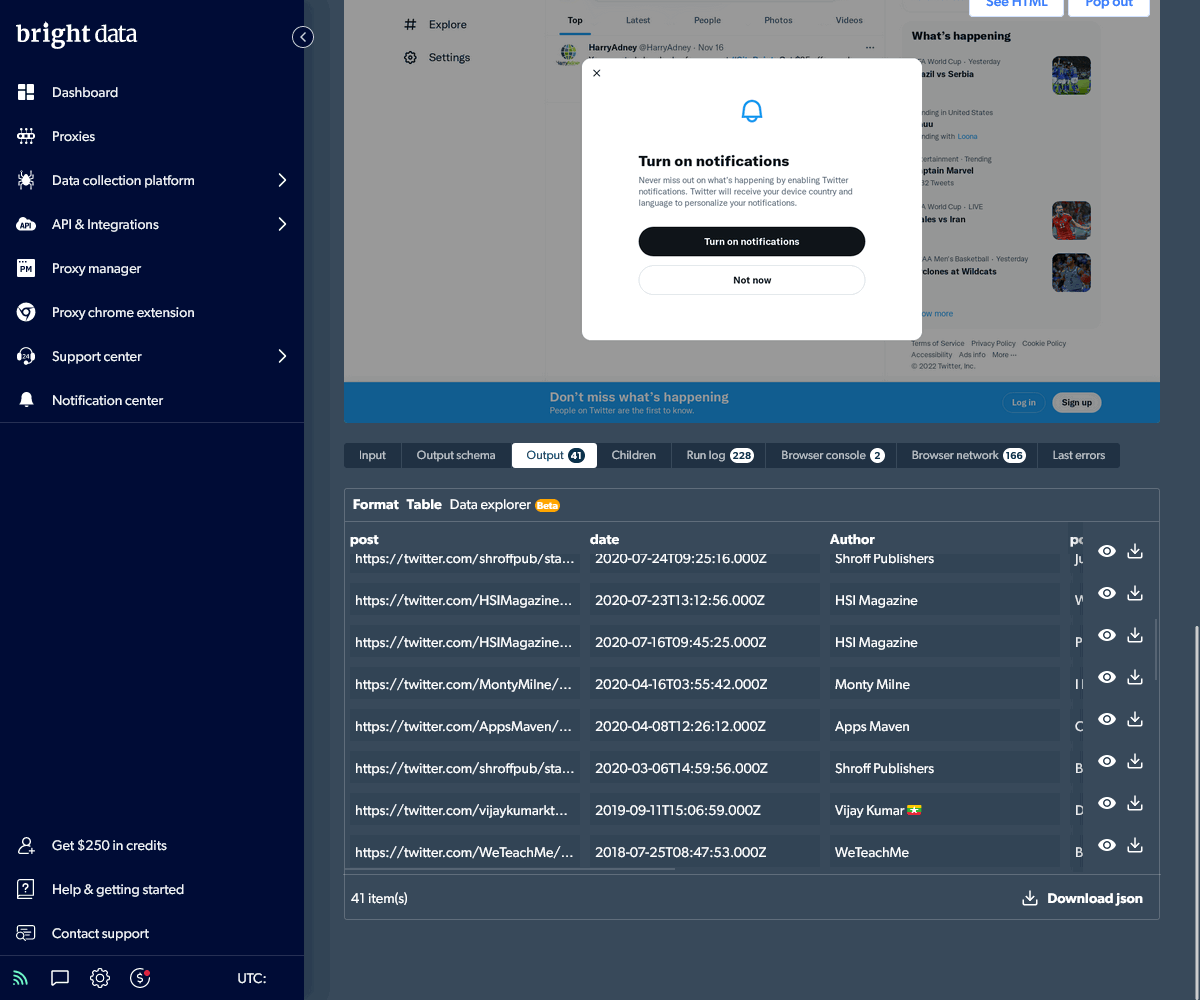
Return to the Collectors panel using the menu or the back arrow at the top. Your new collector is shown.
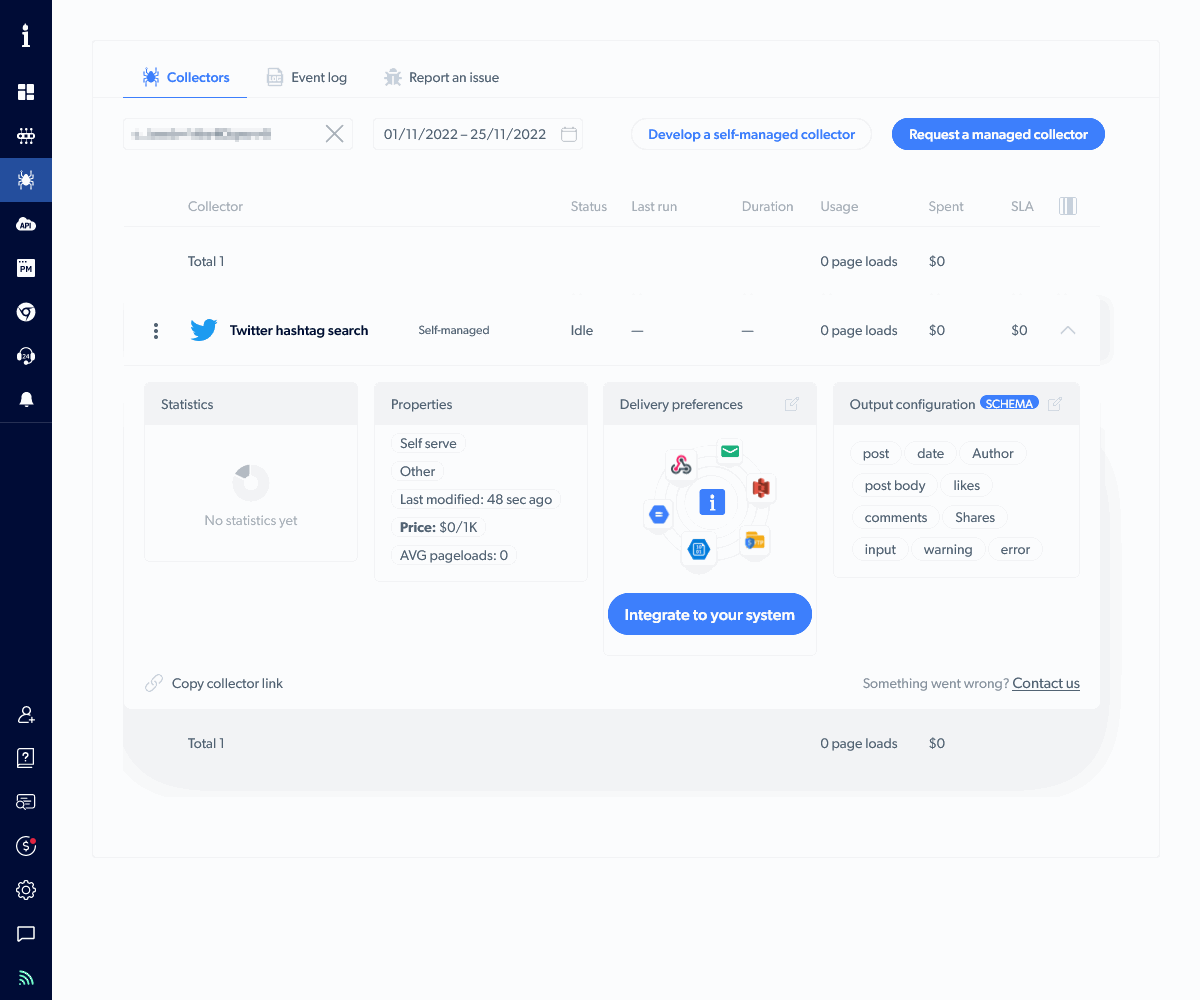
Click the Integrate to your system button and choose these options:
- the Realtime (single request) collection frequency
- JSON as the format
- API download as the delivery
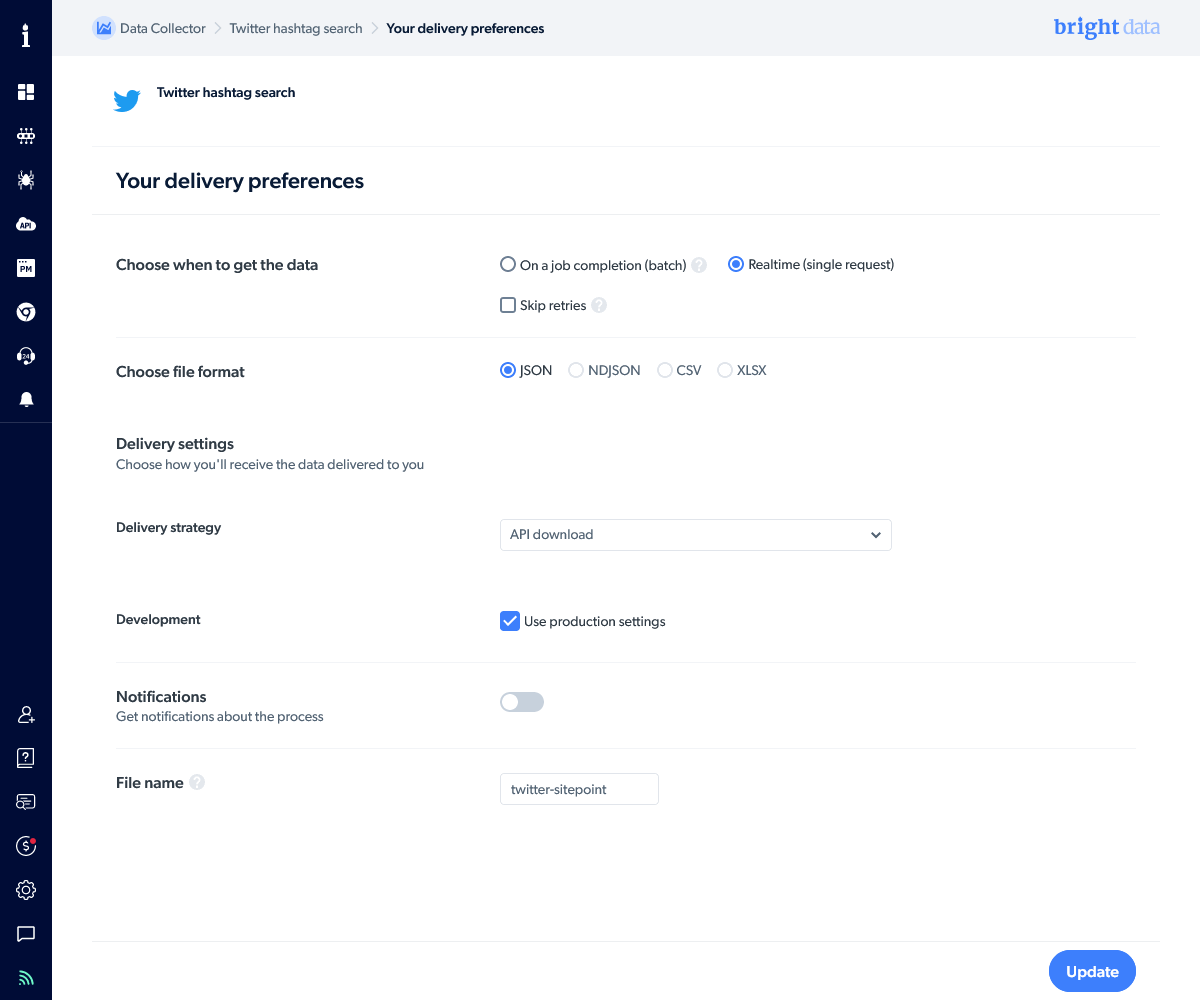
Click Update to save the integration settings and return to the Collectors panel.
Now, click the three-dot menu next to the collector and choose Initiate by API.
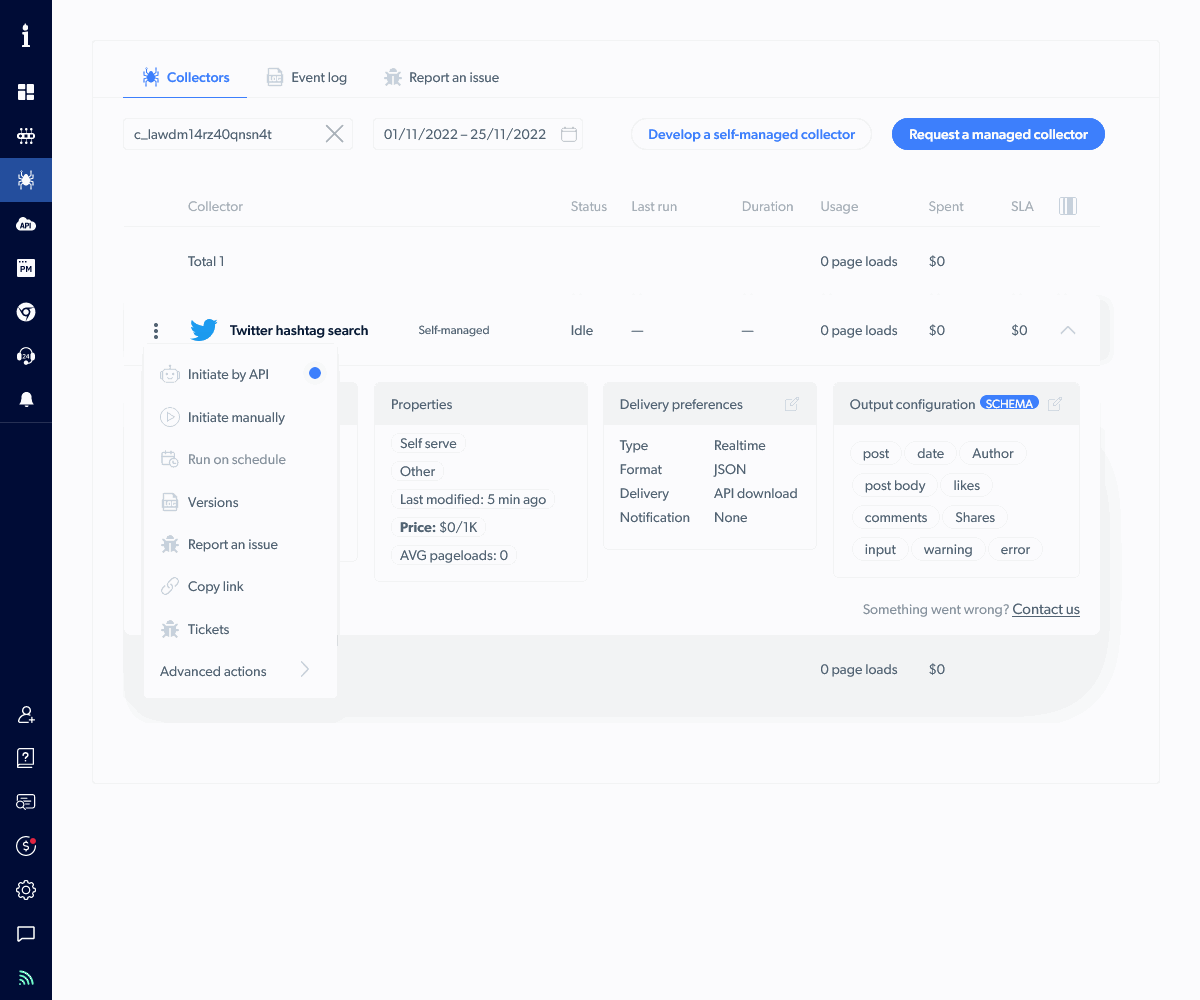
The Initiate by API panel shows two curl request commands.
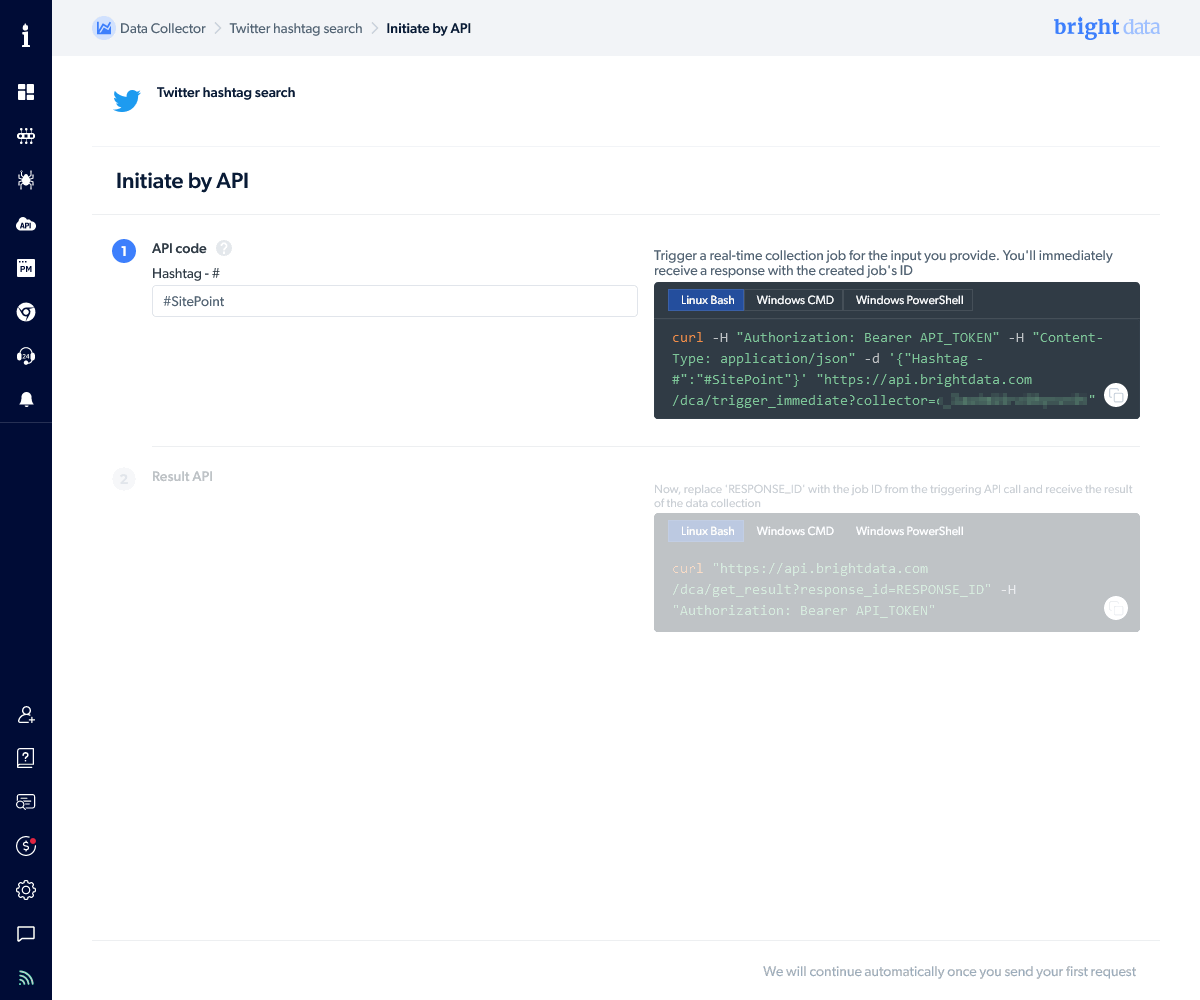
The first command executes the Twitter hashtag collector. It requires the API token you created above. Add it at the end of the Authorization: Bearer header. For example:
curl \
-H "Authorization: Bearer 12345678-9abc-def0-1234-56789abcdef0" \
-H "Content-Type: application/json" \
-d '{"Hashtag - #":"#SitePoint"}' \
"https://api.brightdata.com/dca/trigger_immediate?collector=abc123"
It returns a JSON response with a job response_id:
{
"response_id": "c3910b166f387775934ceb4e8lbh6cc",
"how_to_use": "https://brightdata.com/api/data-collector#real_time_collection"
}
You must pass the job response_id to the second curl command on the URL (as well as your API token in the authorization header):
curl \
-H "Authorization: Bearer 12345678-9abc-def0-1234-56789abcdef0" \
"https://api.brightdata.com/dca/get_result?response_id=c3910b166f387775934ceb4e8lbh6cc"
The API returns a pending message while the collector is executing:
{
"pending": true,
"message": "Request is pending"
}
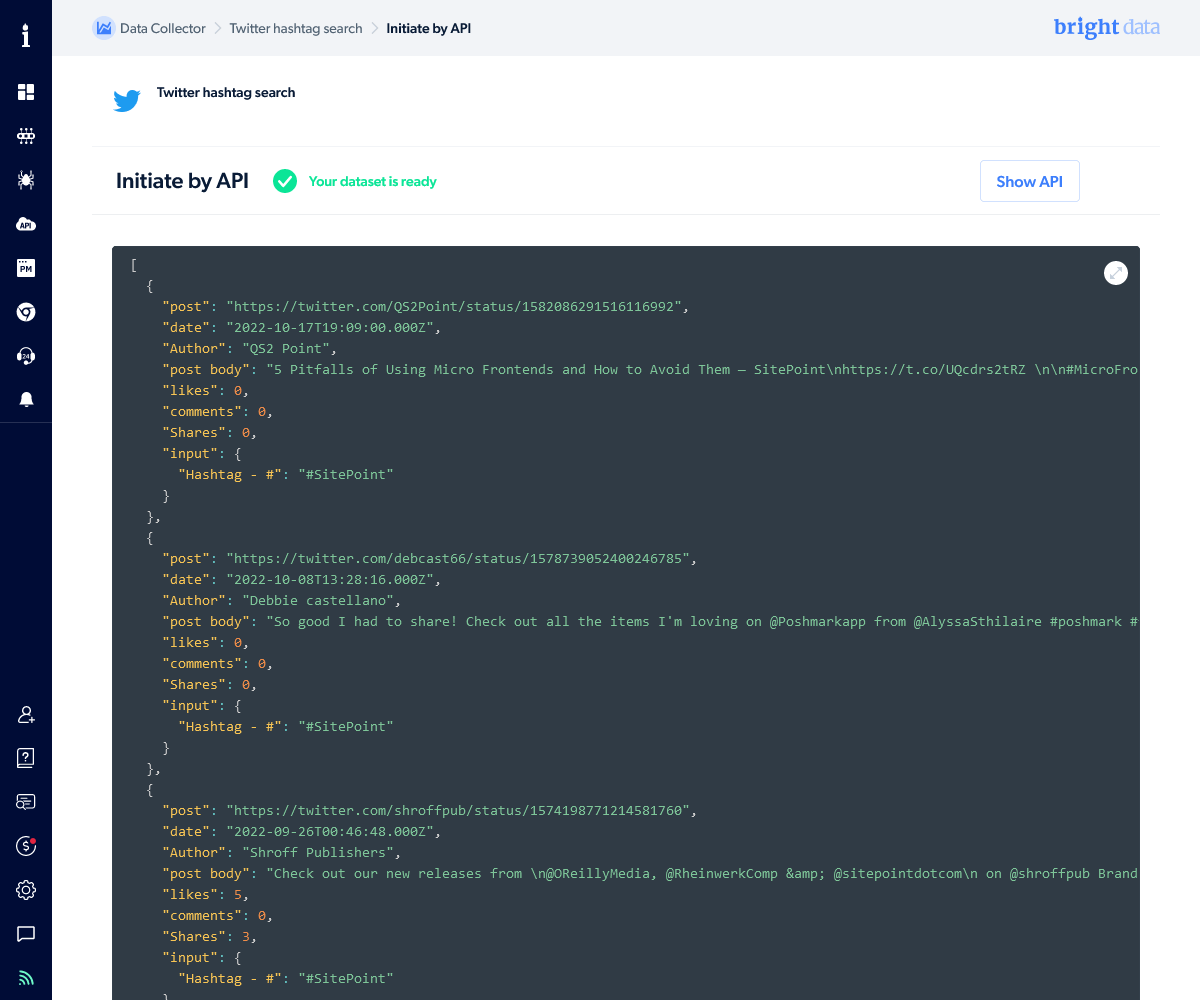
It will eventually return a JSON result containing tweet data when the collector has finished executing. You can import this information into your own systems as necessary:
[
{
"post": "https://twitter.com/UserOne/status/111111111111",
"date": "2022-10-17T19:09:00.000Z",
"Author": "UserOne",
"post body": "Tweet one content",
"likes": 0,
"comments": 0,
"Shares": 0,
"input": {
"Hashtag - #": "#SitePoint"
}
},
{
"post": "https://twitter.com/UserTwo/status/2222222222222",
"date": "2022-10-08T13:28:16.000Z",
"Author": "UserTwo",
"post body": "Tweet two content",
"likes": 0,
"comments": 0,
"Shares": 0,
"input": {
"Hashtag - #": "#SitePoint"
}
},...
]
The result is also available from the Bright Data panels.
Bright Data Proxies
You can leverage Bright Data’s proxy network if your requirements go further than scraping websites. Example use cases:
- you have an Android app you want to test on a mobile network in India
- you have a server app which needs to download data as if it’s a user in one or more countries outside the server’s real location
A range of proxies are available, including these:
- Residential proxies: a rotating set of IPs on real devices installed in residential homes
- ISP proxies: static and rotating high-speed residential IPs in high-speed data centers
- Datacenter proxies: static and rotating datacenter IPs
- Mobile proxies: rotating IPs on real mobile 3G, 4G, and 5G devices
- Web Unlocker proxy: an automated unlocking system using the residential network, which includes CAPTCHA solving
- SERP API proxy: an option for collecting data from search engine results
Each offers options such as auto-retry, request limiting, IP rotation, IP blocking, bandwidth reduction, logging, success metrics, and proxy bypassing. Prices range from $0.60 to $40 per GB depending on the network.
The easiest way to get started is to use the browser extension for Chrome or Firefox. You can configure the extension to use any specific proxy network, so it’s ideal for testing websites in specific locations.
For more advanced use, you require the Proxy Manager. This is a proxy installed on your device which acts as a middleman between your application and the Bright Data network. It uses command-line options to dynamically control the configuration before it authenticates you and connects to a real proxy.
Versions are available for Linux, macOS, Windows, Docker, and as a Node.js npm package. The source code is available on Github. Example scripts on the Bright Data site illustrate how you can use the proxy in shell scripts (curl), Node.js, Java, C#, Visual Basic, PHP, Python, Ruby, Perl, and others.
Proxy use can become complicated, so Bright Data suggests you to contact your account manager to discuss requirements.
Conclusion
Scraping data has become increasingly difficult over the years as websites attempt to thwart bots, crackers, and content thieves. The added complication of location, device, and network-specific content makes the task more challenging.
Bright Data offers a cost-effective route to solve scraping. You can obtain useful data immediately and adopt other services as your requirements evolve. The Bright Data network is reliable, flexible, and efficient, so you only pay for data you successfully extract.
Frequently Asked Questions (FAQs) about Web Scraping
What are the legal implications of web scraping?
Web scraping is a powerful tool for data extraction, but it’s not without its legal implications. The legality of web scraping depends on the source of the data, how it’s used, and the local laws where you operate. Some websites explicitly allow web scraping in their terms of service, while others strictly prohibit it. It’s crucial to respect copyright laws, privacy rights, and terms of service when scraping data. Always seek legal advice before embarking on a web scraping project.
How can I avoid getting blocked while web scraping?
Websites often block IP addresses that send too many requests in a short period. To avoid getting blocked, you can use proxies to distribute your requests across multiple IP addresses. Also, consider setting delays between your requests to mimic human behavior and avoid triggering anti-bot measures. Using a headless browser can also help bypass blocks, as it simulates a real user’s browsing activity.
Can I scrape data from any website?
Technically, you can scrape data from any website that is publicly accessible. However, not all websites allow web scraping. Always check the website’s robots.txt file and terms of service before scraping. If a website explicitly disallows scraping, it’s best to respect their policy and look for alternative data sources.
What is the difference between web scraping and web crawling?
Web scraping and web crawling are two related but distinct concepts. Web crawling is the process of systematically browsing and indexing web pages, typically performed by search engines. On the other hand, web scraping is the act of extracting specific data from web pages for analysis or reuse. While both involve interacting with websites, their goals and techniques are different.
How can I scrape dynamic websites?
Dynamic websites load content using JavaScript, which can make scraping more challenging. Traditional scraping tools that only download the HTML source code may not work. Instead, you’ll need tools that can render JavaScript, like Selenium or Puppeteer. These tools simulate a real browser, allowing you to interact with dynamic content and extract the data you need.
What programming languages can I use for web scraping?
Many programming languages support web scraping, including Python, Java, and Ruby. Python is particularly popular due to its simplicity and the availability of powerful libraries like Beautiful Soup and Scrapy. However, the best language for web scraping depends on your specific needs and existing skills.
How can I handle CAPTCHAs when web scraping?
CAPTCHAs are designed to prevent automated activity, including web scraping. If you encounter a CAPTCHA while scraping, you have a few options. You can use a CAPTCHA solving service, which employs humans to solve CAPTCHAs for a fee. Alternatively, you can use machine learning algorithms to solve CAPTCHAs, although this requires significant technical expertise.
How can I clean and process scraped data?
After scraping, data often needs to be cleaned and processed before it’s useful. This can involve removing duplicate entries, correcting errors, and converting data into a suitable format. Python’s pandas library is a powerful tool for data cleaning and manipulation. It allows you to filter, transform, and aggregate data with ease.
Can I scrape data in real-time?
Yes, you can scrape data in real-time, although it can be more complex than regular scraping. Real-time scraping involves continuously monitoring a website and extracting data as soon as it’s updated. This requires a more robust and scalable infrastructure than regular scraping, as you need to handle a constant stream of data.
How can I respect user privacy when web scraping?
Respecting user privacy is crucial when web scraping. Avoid scraping personal data unless you have explicit consent from the user. Even if a website publicly displays personal data, it doesn’t mean you have the right to scrape and use it. Always respect privacy laws and ethical guidelines when scraping data.
Craig is a freelance UK web consultant who built his first page for IE2.0 in 1995. Since that time he's been advocating standards, accessibility, and best-practice HTML5 techniques. He's created enterprise specifications, websites and online applications for companies and organisations including the UK Parliament, the European Parliament, the Department of Energy & Climate Change, Microsoft, and more. He's written more than 1,000 articles for SitePoint and you can find him @craigbuckler.




