
You’ve probably heard of a bunch of NoSQL databases: Redis, MongoDB, Cassandra, etc., all of which offer a variety of different advantages and come with a set of disadvantages. If you’re building a new application, it’s pretty important to select a database that meets your needs. In this article, we’ll cover RethinkDB, taking a look at how to set up RethinkDB, how it fits into the landscape of NoSQL, and how to use it from Ruby.
Why RethinkDB?
RethinkDB is a JSON document store. That means that it allows you store a bunch of JSON documents and then query them later on. Turns out that RethinkDB isn’t the only document store available. Not even close. Even when the RethinkDB project was started, there were already tons of options available for someone looking for a NoSQL database. So, what’s the point of learning yet another database? To put it simply, RethinkDB combines some of the best features of its competitors and presents a pretty compelling set of advantages.
One of its closest relatives is MongoDB. Mongo quickly grew in popularity because of its focus on developer productivity: creating documents and querying them is incredibly easy to get started with in Mongo. Unfortunately, Mongo has had pretty significant problems with scaling. Granted, some of these problems arise from poor deployment practices but not all the issues raised are unfounded. But, Mongo definitely nailed developer productivity. On the other hand, we have databases like Riak that aren’t as much fun to write code for, but generally scales pretty well without a ton of effort on the part of the Dev Ops team. RethinkDB tries to sit in the middle of this “tradeoff” (there doesn’t seem to be a real reason for this to be a tradeoff): it attempts to provide Mongo-like ease-of-use while still keeping the Dev Ops people happy.
Getting Started
Alright, let’s actually get ourselves a copy of RethinkDB so that we can start using it. Fortunately, they have a nice install page that actually tells us what to do. Please note that Windows is not currently officially supported; a *nix-like system is required (Mac OS X is fine). If you’re on OS X, Homebrew is the way to go:
brew update && brew install rethinkdbFor popular server Linux distributions (e.g. Ubuntu, CentOS, Debian), RethinkDB provides nice binaries. If you don’t fall into any of the usual buckets, then you can build from source, which you can get a copy of:
wget http://download.rethinkdb.com/dist/rethinkdb-1.16.2-1.tgzTo check if rethinkdb installed correctly and to get it running:
rethinkdbTo see the (really nice looking) administrative UI, head over to 127.0.0.1:8080 in your browser. From here, you can take a look at the current status of the “cluster” (which currently consists of one server). We can also fire a couple of queries by heading over to the “Data Explorer” tab.
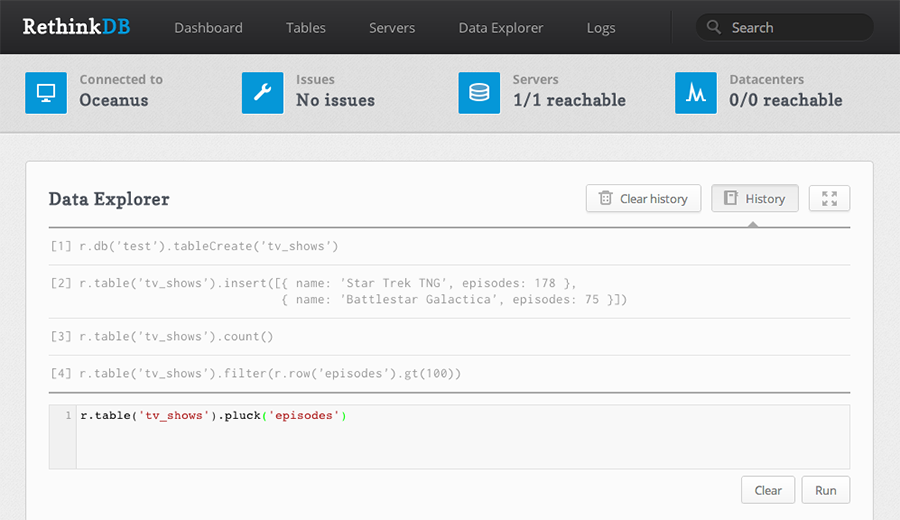
The query editor is really slick; try typing in:
r.dbCreate('testdb')
r.db('testdb').tableCreate('test_table')That creates a database named ‘testdb’ and a table named ‘testtable’ within ‘testdb’. ReQL, RethinkDB’s query language, isn’t really a special language that you have to learn or a special set of JSON objects that you have to put together. Instead, it consists of function calls from the language of your choice. Currently, there are official drivers for Ruby, Python, and Node. Let’s take a look at how to use the Ruby driver.
Ruby Driver
First of all, we need to get the gem:
gem install rethinkdbLet’s make another table inside the “testdb” database we created earlier:
require 'rethinkdb'
include RethinkDB::Shortcuts
conn = r.connect(:host => "localhost", :port => 28015)
r.db("testdb").table_create("people").run(conn)Running this should create the table we want. Let’s break down some of the important lines:
include RethinkDB::ShortcutsThis line lets us use r to call RethinkDB query functions. Just makes it a bit nicer to write query code. If you don’t want to use the shortcuts, you can create your own reference to RethinkDB:
r = RQL.newNext up, we set up a connection with a call to r.connect:
conn = r.connect(:host => "localhost", :port => 28015)Here comes the actual query:
r.db("testdb").table_create("people").run(conn)This line represents a pretty important part of the RethinkDB query DSL. The calls can generally be chained since they all return RQL objects (if you have some experience with Javascript, you’ll probably like this idea). With .db("testdb"), we select the database. Chaining that with .table_create("people") creates the right table for us. But, none of this actually happens until we push on .run(conn) which runs the query against the RethinkDB instance pointed to by the connection object we created earlier.
Okay, so let’s assume you’ve run this query and the table has been created. How can we verify that? We don’t want to create another file just to list the tables in a database, so we’ll use the Ruby REPL (pry or irb, your choice). We first want to set up a connection:
r.connect(:host => "localhost", :port => 28015).replNotice the .repl we tacked on there at the end? That makes it so that RQL will assume that you’re going to be using this connection as the default. This makes dealing with the REPL a lot easier. Let’s check out a query that’ll get us the list of tables inside “testdb”:
r.db('testdb').table_list.runThat should return something like:
["people", "test_table"]Alright, cool. But, wait. There’s a lot missing from the example we just ran. What if stuff goes wrong?
Exception Handling
Stuff goes wrong when dealing with a database all the time. We always want to be sure that our code can withstand, or at least respond to, issues that arise when dealing with RethinkDB. Let’s rewrite our previous example in a bit of a different way:
require 'rethinkdb'
include RethinkDB::Shortcuts
table = "people"
db = "testdb"
begin
conn = r.connect(:host => "localhost", :port => 28015)
rescue Exception => err
puts "Cannot connect to RethinkDB at localhost:28015"
end
begin
r.db(db).table_create(table).run(conn)
rescue RethinkDB::RqlRuntimeError => err
puts "Error occurred in creating #{table} table within #{db}"
puts err
end
begin
puts "Tables inside #{db}: ", r.db(db).table_list().run(conn)
rescue RethinkDB::RqlRuntimeError => err
puts err
ensure
conn.close
endBasically, we’ve wrapped everything in exceptions and also added an ensure clause so we can close the connection to RethinkDB. You can think of RethinkDB exceptions just like any other exception, except that they’re generally really important. So, if you choose to ignore (i.e. don’t rescue) a given exception, understand the repercussions completely.
Documents
Alright, how do we actually put stuff in our table? As you might recall, RethinkDB is a document store, meaning that it stores JSON objects. Let’s put a person in our people table (I’ll present the REPL form but moving it into code just requires passing in the connection object to run):
res = r.db("testdb").table("people").insert({:name => "Dhaivat"}).runThat should have returned something like:
{"deleted"=>0, "errors"=>0, "generated_keys"=>["417b5b3e-c107-4577-acfc-cd11a76f9174"], "inserted"=>1, "replaced"=>0, "skipped"=>0, "unchanged"=>0}Notice that’s a Ruby hash so it’s pretty clear how we’d get values out of that structure (e.g. res['generated_keys'] gives the list of primary keys generated by the insert). There are couple of important parts of the structure. First of all, generated_keys is a list of the primary keys (in this case, the list contains only one element) that you can later use to find the same document from the table. Secondly, a positive value for inserted tells us that an element was inserted with the query. To insert multiple documents with one query, just stick them in a list and pass them to .insert. One of the most important points here is that RethinkDB couldn’t care less what structure your documents have. Unlike MySQL (and other RDMBS) where you specify table structure, RethinkDB lets you just wing it every time you put stuff in your database. This means that either your DB-interacting code has to be very careful or you have to make sure that you don’t keep old structures sticking around too long. As an exercise, add documents for “John”, “Jane” and “George”.
Inserting documents is pretty easy. How about getting them back out again? We can get an iterator pointing to a certain point in the table. If we want to iterate over all the objects in the table:
itr = r.db('testdb').table('people').run
itr.each do |document|
p document
endWhat if we want to filter according to some constraint? All we have to do is build a query that specifies the filter:
itr = r.db('testdb').table('people').filter {|person| person['name'].eq("John")}.run
itr.each do |document|
p document
endHere, we use the filter {|person| person['name'].eq("John")} in order to specify a boolean condition. Notice that we do equality comparison with .eq because RQL isn’t happy with us using ==. Basically, any boolean condition we can cook up can be used as part of a filter. We can delete documents in a similar way:
r.db('testdb').table('people').
filter {|person| person['name'].eq("John")}.
delete.runWe can query based on id really easily:
itr = r.db('testdb').table('people')
itr.get(id)Update works in a similar way:
itr.update({name: "Dhaivat Pandya"}).runWhatever documents are iterable with itr will then be updated so that the name field is set to "Dhaivat Pandya".
A Note About RQL
If you’re used to SQL, you might be wondering what the point of filtering is if we’ve already pulled back the entire table first. Well, we haven’t. Everything that comes before a .run is put together into one query, sent over to the server, which returns back only the stuff you asked for. Long story short, all queries run on the server. My experience with RQL has been quite pleasant; query chaining, easy filtration, etc. make RQL enjoyable to use.
Wrapping It Up
This article should serve as a pretty quick introduction to RethinkDB. But, there’s a tremendous amount of stuff still left untouched, e.g. table joins, map-reduce, etc. In future articles, we’ll be delving into all these exciting topics.
Drop any questions in the comments below.
 Dhaivat Pandya
Dhaivat PandyaI'm a developer, math enthusiast and student.



