 This article is an excerpt from the book Professional Perl Development from WROX Press. See Kevin Yank’s review here.
This article is an excerpt from the book Professional Perl Development from WROX Press. See Kevin Yank’s review here.
The exponential growth of the web in recent years has led to a number of conflicting demands on a site’s development team. On the one hand, users expect more than simple static content – they demand interactivity through forms, search facilities, customization of pages, and so on. At the same time, however, users anticipate such things as an aesthetically pleasing layout, easy navigation, and a similar look and feel among related pages. These demands in fact underline a fundamental direction that the Web is heading in – a separation of content from presentation. This separation in principle can make development of a site easier; first handle the generation of dynamic content, and then address how the results are to be presented. Ultimately however, one has to make an interface between the two – how to input the dynamic data into an HTML page.
In many cases, such as a search facility that looks up a query in some database, this interface can be handled through CGI scripts. Of course, Perl, and in particular the CGI.pm module (see Chapter 1), is justifiably famous for this. So much so that many bookstores, web sites, and news group posters consider Perl and CGI programming to be synonymous (much to the chagrin of, among others, regular posters to comp.lang.perl.misc). However, for more complicated applications and/or for large numbers of pages, an approach based on CGI scripts is not always satisfactory for a number of reasons:
- It does not always scale well.
- It can place large demands on the server.
- It can be difficult to manage for large sites.
A primary reason for these shortcomings is that the separation of content and presentation is not always so clean in a CGI script. Indeed, often it is just one script that generates both the content and the HTML tags, which makes it difficult to change the presentation or the content individually. There are, however, a number of different classes of solutions available within Perl that were developed to address this problem:
- HTML::Template
- Template
- HTML::Mason
- HTML::Embperl
- Apache::ASP
These approaches will be the main subject of this chapter. All of these modules are available on CPAN, and for UNIX can be installed in the usual ways. In a Win32 environment we may need an expensive C compiler to build and install them (particularly Visual C++ if we would also like to use them with mod_perl, described in Chapter 2). If we don’t have VC++, pre-built binaries of these modules are available through links listed at http://perl.apache.org/, including ppm (Perl Package Manager) files for Win32 ActivePerl.
Of course, constructing web pages can be handled purely from a CGI/mod_perl approach without the use of modules, such as those that will be described here for embedding Perl in a web page. The advantages of using these modules is that they are designed specifically for a web environment, and so have many optimal constructions and shortcuts built in that have been found very useful in this context. Also, many users have tested these modules extensively in this environment. Once we learn the syntax of a particular module, we are able to write components that are easily maintainable, reusable, and scalable and this has distinct advantages.
Templates
The philosophy of a template file is to make up a template describing the basic HTML layout that we wish to use. Within this file there are special indicators, which will be filled in dynamically from some script. There are a number of Perl modules available that can be used for this purpose, and like the question of ‘Which editor should I use?’, deciding which is best is often a matter of personal taste. Here we describe two basic modules to give a flavor for how they are used. For additional details and a list of further such modules, we ought to browse CPAN – a convenient way to do this is through a CPAN search engine such as:
- http://search.cpan.org
- http://www.perldoc.com
- http://theoryx5.uwinnipeg.ca/mod_perl/cpan-search
‘HTML::Template’
A basic template with this module has the following form:
<HTML>
<HEAD><TITLE>Test Template</TITLE></HEAD>
<BODY>
<TMPL_INCLUDE NAME="header.tmpl">
Please contact the person listed below: <BR>
<A HREF="mailto:<TMPL_VAR NAME=email>">
<TMPL_VAR NAME=person> </A> <TMPL_INCLUDE NAME="footer.tmpl">Common headers and footers can be inserted with the <TMPL_INCLUDE NAME=”file”> syntax, as indicated. If we call this template greeting1.tmpl, then we can generate a dynamic page using it as in the following script:
#!/usr/bin/perl
# htmltemplate.pl
use warnings;
use strict;
use HTML::Template;
my $template = HTML::Template->new(filename => 'greeting1.tmpl');
$template->param('email', 'bill@nowhere.com');
$template->param('person', 'William');
print "Content-Type: text/htmlnn";
print $template->output; The output method is then used to generate the filled-in template page.
‘Template’
In the Template module (part of the Template-Toolkit package), the basic HTML template has variable placeholders indicated by the [% ... %] syntax, as in the following example:
[% INCLUDE header %]
Please contact the person listed below: <BR>
<a href="mailto:[% email %]">[% person %]</a>
[% INCLUDE footer %]Note the use of INCLUDE to include common headers and footers. If we call this template greeting2.html, then we can generate a dynamic page using this template as in the following script:
#!/usr/bin/perl
# template.pl
use warnings;
use strict;
use Template;
$| = 1;
print "Content-type: text/htmlnn";
my $file = 'greeting2.html';
my $vars = {
'email' => 'bill@nowhere.com',
'person' => 'William',
};
my $template = Template->new({
INCLUDE_PATH => '/home/me/templates:/home/me/lib',
});
$template->process($file, $vars) || die $template->error();Note the use of INCLUDE_PATH when creating the Template object to specify which directories to search for the template files. The process method is the basic workhorse of the module – it takes the template specified by $file, and applies the variable substitutions in this file specified by $vars.
These modules, and others, support more than just simple variable substitutions. For example, in the Template module, simple loop constructions and conditionals can be incorporated. If in the script we set the following:
$vars = {
'people' => [ 'Tom', 'Dick', 'Larry', 'Mary' ],
}; and in the template file:
[% FOREACH person = people %]
Hello [% person %]
[% END %] the script will iterate over the members of the people array reference and print out the corresponding value (individual members can be accessed in the template as, for example, [% people.1 %], which will correspond to Dick in the above example). In addition to insertion, replacement, loops, and conditionals, the Template module has directives for dynamically invoking other template files, a macro capability, exception raising and handling, and some invocation of Perl code. For example, the processing of form data can be done within the Template module through the CGI.pm module simply by including the following in the template file:
[% USE CGI %] The methods of the CGI.pm module can then be accessed through syntax such as:
[% CGI.header %]
[% CGI.param('parameter') %] These template modules can be used in a mod_perl-enabled server to speed up generation of the pages. One of the advantages of these approaches is that a relatively clean separation between content and display is obtained. Due to the relative simplicity of the template indicators, it is reasonable to have, for example, a web designer work on a template file and a programmer work on the data generation. However, for more complex situations, a greater degree of programming constructions may be required and these will be described in the next sections.
‘HTML::Mason’
This module, which is described in more detail at http://www.masonhq.com/, uses the idea of components, which are mixtures of HTML, Perl code, and Mason commands. A top-level component represents an entire page, while smaller components can be used to generate snippets of HTML to be used in a larger component. Such a design can simplify site management significantly, as changing a shared sub-component can instantaneously change a large number of pages that use this component.
Embedding Perl into Web Pages 355 After installing the module, directives such as those in the following sample are placed in Apache’s httpd.conf file:
PerlRequire /path/to/Mason/handler.pl # bring in the handler.pl file
Alias /mason/ "/home/www/mason/" # create a special directory for
# Mason files
<Location /mason>
SetHandler perl-script
PerlHandler HTML::Mason
</Location> This assumes that we have a mod_perl-enabled Web server. The handler.pl file is used to start Mason and to define a routine to handle the requests passed to it under the Location directive. The following is a sample handler.pl file:
#!/usr/bin/perl
# handler.pl
package HTML::Mason;
use HTML::Mason;
use HTML::Mason::ApacheHandler;
use strict;
use warnings;
# list of modules that we want to use from components (see Admin
# manual for details)
{
package HTML::Mason::Commands;
use DBI;
use CGI qw(:all);
use CGI::Cookie;
use Fcntl;
use MLDBM;
use LWP;
}
# create Mason objects
my $parser = new HTML::Mason::Parser;
my $interp = new HTML::Mason::Interp (parser=>$parser,
comp_root => '/home/www/mason',
data_dir => '/usr/local/apache/mason');
my $ah = new HTML::Mason::ApacheHandler (interp => $interp);
chown (scalar(getpwnam "nobody"), scalar(getgrnam "nobody"),
$interp->files_written);
sub handler
{
my ($r) = @_;
my $status = $ah->handle_request($r);
return $status;
}
1; The handler.pl file typically creates three objects:
- A parser – transforms components into Perl subroutines
- An interpreter – executes these subroutines
- A handler – routes mod_perl to Mason
The comp_root directory is a virtual root for Mason’s component file system, like the server’s DocumentRoot directive (they may be the same). The data_dir directory will be used by Mason to generate various data files. Note the convenient ability in this file to load modules to be used in other components.
We illustrate the use of Mason with a simple example, which prints out the values of the environment variables:
<%perl>
my $col1 = "Key";
my $col2 = "Value";
</%perl>
<h2><% $headline %></h2>
<table width=450>
<tr <& .bgcolor &>>
<th align=left><% $col1 %></th>
<th align=left><% $col2 %></th>
</tr>
% foreach my $key (sort keys %ENV){
<tr <& .bgcolor &>>
<td valign=top><b><& .font, val=>$key &></b></td>
<td><& .font, val=>$ENV{$key} &></td>
</tr> % }
</table>
<%init>
my $headline = "The Environment variables:";
</%init>
<%def .font>
<font size=1 face='Verdana, sans-serif'> <% $val %> </font>
<%args>
$val=>""
</%args>
</%def>
<%def .bgcolor>
% my $color= $x++%2?$colors[0]:$colors[1];
bgcolor="#<% $color %>"
</%def>
<%once>
my $x = 0;
my @colors = ('FFFFFF', 'CCCCCC');
</%once>If we place this file, say environ1.html, in the directory specified by the /mason location in httpd.conf, and call it with http://localhost/mason/environ1.html, the following results are obtained:

The various sections of the file are described below:
- The
<%perl>...</%perl>section is used for a block of Perl code. In it we declare the variables$col1and$col2. - After this, we give the level 2 heading using the variable $headline, which is initialized in the
<%init>...</%init>block (this is executed as soon as the component is loaded). Note the use of<%...%>to echo the value of $headline within a line of HTML code. - Next we set up the table used to print out the values of the environment variables. Headings for this table use the component
.bgcolor(note the convention of using a leading period in defining component names). Components are called with the syntax<& component_name, [variables] &>; this particular component is defined in a<%def>...</%def>section. Note the use of a leading % to denote a single line of Perl code. - We next set up a loop to print out all available environment variables. As well as the .bgcolor component used previously, this block uses the .font component. This particular component also uses a
<%perl>...</%perl>section to handle passing of arguments from the<& component_name, [variables] &>call. - Finally, we use a
<%once>...</%once>section to set the variables used in determining the background color for the table row.
If we look carefully at the screenshot we will notice that the page has a title and a line, which we didn’t set explicitly. What happened is that we have also defined a special component file called autohandler, which gets called every time a top-level component is invoked and which is interpreted before the called components are interpreted. The component used in this particular example, which should also be placed in the directory specified by the /mason location in httpd.conf, is listed below:
<HTML>
<HEAD> <TITLE>Embedding Perl into Web Pages with HTML::Mason</TITLE>
</HEAD>
<BODY BGCOLOR="#FFFFFF">
<B>Mason Example:</B>
<% $m->call_next %>
</BODY>
</HTML> The <% $m->call_next %> line passes control to the next component (in this case, the original page called). These handlers are directory based, meaning that it is very easy to change the layout of a large number of pages just by changing this particular component.
A Longer Example
As a more involved example of using HTML::Mason, we illustrate the use of a telephone book lookup form. In this example, the data is assumed to be in a file /usr/local/data/phone.txt, with one entry per line containing the name and phone number of a person, separated by the # symbol. This is an example of what it should look like:
Andrew Logan#377-0971 Matt Jones#598-6788 We split this application across four files – a master file (called phone.html), a form through which a user enters a query (called form), a lookup script that gathers the data from the database (called lookup.html), and finally a script to print out the results (called print_it). We will also have a header file, header, and a footer file, footer, called though the autohandler template file. Also in this example, we illustrate the use of cookies in saving session data across invocations of the script. All files are to be placed in the directory specified by the /mason location in httpd.conf.
Using the same Apache configuration as before, we first give the autohandler template file:
% my $title = 'My HTML::Mason demo';
<& header, title => $title &>
<H3>Phone book example</H3>
<% $m->call_next %>
<& footer &> The header file, called with a parameter title through the syntax <& header, title => $title &>, is:
<HTML>
<HEAD><TITLE><% $title %></ TITLE ></HEAD>
<body bgcolor="#ffffff" link="#ff5599" vlink="#993399">
<BR>
<%ARGS>
$title => undef
</%ARGS> And the footer file is:
<P>
Comments to
<A HREF="mailto:me@my.address.com">me</A>
are welcome.
</BODY>
</HTML> Note the use of the <%ARGS>...</%ARGS> construction, which is used to define arguments to be passed into the file. The master file by which the script is called, phone.html, contains:
% my $name = param('name');
% if (! $name) {
<& form &>
% }
% else {
% $r->header_out('Set-Cookie', "name = $name");
<& lookup.html, name => $name &>
% } We begin here by checking, via the param method of the CGI.pm module (pulled in through handler.pl), if a value has been entered for the name parameter. If it hasn’t, we print out the form contained in the file form. If a value has been entered, we set a cookie via the mod_perl-specific call $r->header_out('Set-Cookie', "name = $name") to save this value across sessions, and then call lookup, which will query the database and print out the results. Note that we pass to this file the variable $name.
The file form used to print out the form by which the user enters the query contains:
% my $val = cookie(-name => 'name');
<FORM>
<TABLE><TR>
<TD>Please enter the name:</TD>
<TD>
<INPUT TYPE="text" NAME="name" SIZE=30 VALUE="<% $val %>">
</TD>
</TR><TR>
<TD COLSPAN=2>
<INPUT TYPE="submit" VALUE="Search!"> </TD></TR></TABLE>
</FORM> This uses the cookie method of the CGI.pm module to retrieve the value of the cookie associated with the name parameter, if it is present. This value is used as the default for the textfield box in which the user enters the query.
When the user enters a value and submits the data, the file lookup.html will be called. This file is given by:
<%perl>
my %match;
open (PHONE, "/usr/local/data/phone.txt") or
die "Cannot open phone.txt: $!";
while (<PHONE>) {
my @a = split /#/, $_;
next unless $a[0] =~ /$name/;
$match{$a[0]} = $a[1];
}
close (PHONE);
</%perl>
<& print_it, match => %match, name => $name &>
<%ARGS>
$name => undef
</%ARGS> In this file, we first open up the file and cycle through the entries, saving those entries that match the search criteria in the hash %match. Note that, as with any CGI script, some form of taint checking should be done on any user-supplied input – see perldoc perlsec for a discussion. After the results are obtained, the file is closed and print_it is called, which will print out the results (note that a reference to the %match hash and the original query term $name are passed to this file). The print_it file is as follows:
<%perl>
my @names = sort keys %$match;
my $num = @names;
if ($num > 0) {
my $string = sprintf(
"<B>%d</B> match%s for "<B>%s</B>" %s found:",
$num, ($num > 1 ? 'es' : ''), $name,
($num == 1 ? 'was' : 'were') );
</%perl>
<% $string %>
<TABLE WIDTH="40%">
<TR><TD COLSPAN=2><HR></TD></TR>
<TR><TH ALIGN="LEFT">Name</TH>
<TH ALIGN="LEFT">Number<TH></TR> % foreach (@names) {
<TR>
<TD ALIGN="LEFT"><% $_ %></TD>
<TD ALIGN="LEFT"><% $match->{$_} %></TD>
</TR>
% }
<TR><TD COLSPAN=2><HR></TD></TR>
</TABLE>
% }
% else {
Sorry nothing matched "<B><% $name %></B>".
% }
% my $url = url;
Try <A HREF="<% $url %>">another search</A>.
<%ARGS>
$match => undef
$name => undef
</%ARGS> In this file we first construct an array @names from the passed %match hash reference, which contains the names of the successful matches. We also set a variable $num equal to the number of successful matches obtained. If there were any, we print out the results in a table. If there were no matches we report that as such. Finally, at the bottom of this page we provide a link back to the original script through the url function of the CGI.pm module.
Some screenshots of this application in action appear below. When the address http://localhost/mason/phone.html is first requested, the basic form is presented through which the user enters a query:
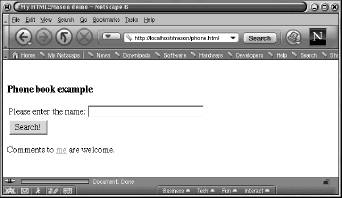
Upon entering a query (say M) and submitting the form, the results are then presented:
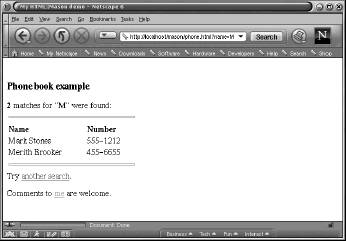
If the user selects the another search link, the original query form is presented, but with the textfield filled in via the cookie, with the default value from the original query.
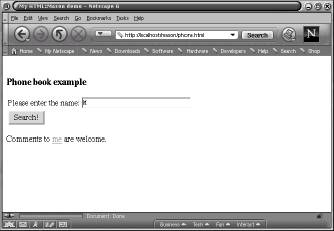
These examples just show the basic structure of Mason. For more complex examples, we can refer to the Mason web site at http://www.masonhq.com/ and also to the examples contained within the source distribution.
‘HTML::Embperl’
HTML::Embperl is another approach to being able to embed Perl code in HTML pages. For more details than are provided here, see the documentation at http://perl.apache.org/embperl/. After installation of the module, directives such as the following samples are to be placed into Apache’s httpd.conf file:
PerlModule HTML::Embperl
Alias /embperl/ "/home/www/embperl/"
<Location /embperl>
SetHandler perl-script
PerlHandler HTML::Embperl
Options ExecCGI FollowSymLinks
</Location>
PerlModule HTML::EmbperlObject
<Location /embperl/object>
PerlSetEnv EMBPERL_OBJECT_BASE base.html
PerlSetEnv EMBPERL_FILESMATCH ".htm.?|.epl$"
PerlSetEnv EMBPERL_OPTIONS 16
SetHandler perl-script
PerlHandler HTML::EmbperlObject
Options ExecCGI
</Location> This assumes a mod_perl-enabled server. Any file placed in the /embperl directory will be parsed by the HTML::Embperl Apache handler first. Any file that matches the rule stated by the EMBPERL_FILESMATCH environment variable and placed in the /embperl/object directory will be delivered through the HTML::EmbperlObject Apache handler.
To give a flavor of how Embperl is used, we give the simple example of printing out the values of the various environment variables:
[!
$x = 0;
@colors = ("#FFFFFF", "#CCCCCC");
sub _color{
return $x++ % 2 ? $colors[0] : $colors[1];
}
!]
<br>
<TABLE width=450>
[-
@k = sort keys %ENV;
@headlines = ('Key', 'Value');
-]
<tr bgcolor="[+ &_color() +]">
<th align=left>[+ $headlines[$col] +]</th>
</tr>
<TR bgcolor="[+ &_color() +]">
<TD><font size=1 face="Verdana, sans-serif">
[+ $k[$row] +] </font></TD>
<TD><font size=1 face="Verdana, sans-serif">
[+ $ENV{$k[$row]} +] </font></TD>
</TR>
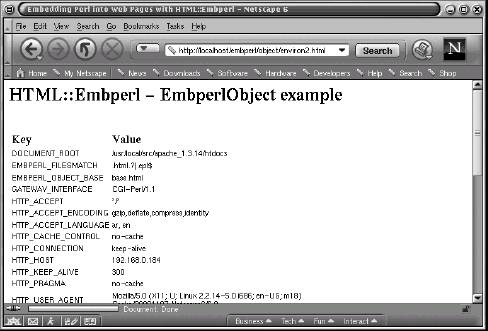
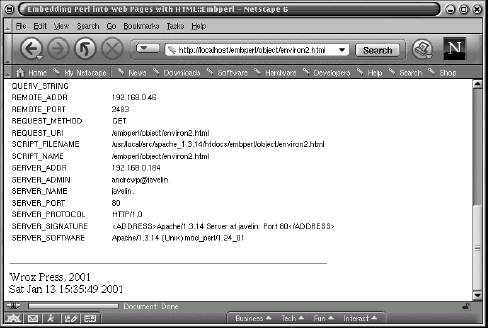
</TABLE> If this file, say environ2.html, is placed in the directory specified by the /embperl location in httpd.conf, the result of calling http://localhost/embperl/environ2.html is:
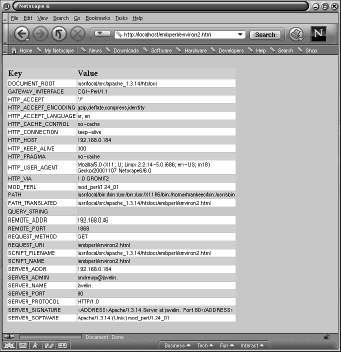
The meaning of the various lines of the Embperl page are described below:
- The syntax
[!...!]first encountered is used to compile (once) a block of Perl code. The first such block is used to set up the colors used in the table rows and to define a Perl subroutine that will determine the particular color to use. - Next is the
[-...-]syntax and this is used to compile a block of Perl code. This particular one establishes arrays to be used to set the table headings and the value of the various environment variables. - The color subroutine is called through the
&_colorsyntax. This is wrapped within a[+...+]block, which will print out the returned value. - A very powerful feature of
Embperlillustrated in this example is automatic looping over of variables in a table context. In the first illustration, which sets the table headings, as many<TH>tags will be generated as needed, based on the input from the@headlinesarray. The iteration is done with the special global variable $col as the iterator, which holds the number associated with the current column. - This same feature of automatic looping is also illustrated for the table rows, where in this case the required number of rows is automatically generated from input from the %ENV hash. Here, the special global variable
$rowis used as the iterator, which holds the number associated with the current row.
The templating capabilities of Embperl are based on the use of the HTML::EmbperlObject Apache handler, which functions in a manner similar to HTML::Mason‘s autohandler. To illustrate this, we place the above file, say environ2.html, in the /embperl/object directory specified in httpd.conf. We then construct a file, in the same directory, specified by EMBPERL_OBJECT_BASE (in our example, base.html), which will hold the master template that will be applied to any requested page. A sample base.html appears below:
<HTML>
<HEAD>
<title>Embedding Perl into Web Pages with HTML::Embperl</title>
</HEAD>
<BODY BGCOLOR="#FFFFFF">
[- Execute ('header.html') -]
[- Execute ('*') -]
[- Execute ('footer.html') -]
</BODY>
</HTML> Here we have included two other files, header.html and footer.html, defining an included header and footer. These are to be placed in the same directory as base.html. An example header.html is:
<H2>HTML::Embperl - EmbperlObject example</H2> An example footer.html is:
<BR>
<HR size=1 noshade width=450 align=left>
Wrox Press, 2000<BR>
[+ localtime +]Embedding Perl into Web Pages 365 Finally, requesting the http://localhost/embperl/object/environ2.html will generate the following results. The screenshots show the header and footer files implemented:
A Longer Example Revisited
As a more involved example of using HTML::Embperl, we illustrate the use of the telephone book lookup form. As before, the data is assumed to be in the file /usr/local/data/phone.txt, with one entry per line containing the name and phone number of a person, separated by the # symbol. We split this application across four files – a master file, phone.html, the query form, form.html, a lookup script, which gathers the data from the database, lookup.html, and a script to print out the results, print_it.html. In this example we also illustrate the use of cookies in saving session data across invocations of the script.
Within the <Location> directive specifying /embperl/object we also added:
PerlSetEnv EMBPERL_OPTIONS 16 This directs Embperl not to pre-process the source for Perl expressions and is useful if we use a text editor for writing code. We should not set this if we use a WYSIWYG editor, which inserts unwanted HTML tags and escapes special characters automatically (for example, > to >). See the HTML::Embperl documentation for further details on this and other options.
All files, using the previous Apache configuration, are to be placed in the directory specified by the /embperl/object location. The base file base.html is given by:
[- Execute 'header.html' -]
<H3>Phone book example</H3>
[- Execute ('*') -]
[- Execute 'footer.html' -]The header.html is:
[-
$title = 'My HTML::Embperl demo';
-]
<HTML>
<HEAD><TITLE>[+ $title +]</TITLE></HEAD>
<body bgcolor="#ffffff" link="#ff5599" vlink="#993399">
<BR> And, footer.html is:
<P>
Comments to
<A HREF="mailto:me@my.address.com">me</a>
are welcome.
</BODY>
</HTML> The master file by which the script is called, phone.html, consists of:
[$if ! $fdat{name} $]
[- Execute 'form.html' -]
[$else$]
[-
$http_headers_out{'Set-Cookie'} = "name=$fdat{name}";
Execute({inputfile => 'lookup.html', param => [$fdat{name}]});
-]
[$endif$]We begin here by checking the special %fdat hash (containing the form data, which Embperl automatically supplies) for a value having been entered for the name parameter. If it hasn’t, we print out the form contained in the include file form.html. If a value has been entered, we set a cookie via $http_headers_out{'Set-Cookie'}= "name=$fdat{name}" to save this value across sessions, and include a file lookup.html, which will query the database and print out the results. Note how we pass to this file the variable $name through the Execute({inputfile => 'lookup.html', param => [$fdat{name}]}) call. This example also illustrates how to set up if...else blocks within Embperl through the [$if$]...[$else$]...[$endif$] syntax (a similar syntax is available for while loops).
The file form.html used to print out the form by which the user enters the query is given by:
[- use CGI qw(cookie);
$val = cookie(-name => 'name');
-]
<FORM>
<TABLE><TR>
<TD>Please enter the name:</TD>
<TD>
<INPUT TYPE="text" NAME="name" SIZE=30 VALUE="[+$val+]">
</TD>
</TR><TR>
<TD COLSPAN=2>
<INPUT TYPE="submit" VALUE="Search!">
</TD></TR></TABLE>
</FORM> This uses the cookie method of the CGI.pm module to retrieve the value of the cookie associated with the name parameter, if it is present. This value is used as the default for the textfield box in which the user enters the query.
When the user enters a value and submits the data, the file lookup.html will be called. This file is shown below:
[-
$name = $param[0];
open (PHONE, "/use/local/data/phone.txt")
or die "Cannot open phone.txt: $!";
while (<PHONE>) {
my @a = split /#/, $_;
next unless $a[0] =~ /$name/;
$match{$a[0]} = $a[1];
}
close (PHONE);
Execute({inputfile => "print_it.html", param => [%match, $name]});
-] First it captures the $name variable passed to it in the master file via the @param array. It then opens up the database file and cycles through the entries, saving those entries that match the search criteria in the hash %match. After the results are obtained, the file is closed and a file print_it.html is included, which will print out the results (note that a reference to the %match hash containing the results and the original query term $name are passed to this file through the Execute call). The print_it.html file is as follows:
[-
$match = $param[0];
$name = $param[1];
@names = sort keys %$match;
@nums = map {$match->{$_}} @names;
$num = @names;
-]
[$if ($num > 0) $]
[-
$string = sprintf(
"\<B\>%d\</B\> match%s for \"\<B\>%s\</B\
>\" %s found:",
$num, ($num > 1 ? 'es' : ''), $name, ($num == 1 ? 'was'
: 'were') );
-]
[+ $string +]
<HR>
<TABLE WIDTH="40%">
<TR><TH ALIGN="LEFT">Name</TH>
<TH ALIGN="LEFT">Number<TH></TR>
<TR>
<TD ALIGN="LEFT">[+ $names[$row] +]</TD>
<TD ALIGN="LEFT">[+ $nums[$row] +]</TD>
</TR>
</TABLE>
<HR>
[$else$]
Sorry - nothing matched "<B>[+ $name +]</B>".
[$endif$]
[- use CGI qw(url);
$url = url;
-]
Try <A HREF="[+ $url +]">another search</A>. In this file we first capture the variables passed into it from lookup.html via the @param array. For later use we construct two arrays, @names and @nums, from the passed %match hash reference. These arrays contain respectively, the names and the numbers of the successful matches. We also set a variable $num equal to the number of successful matches obtained. If there were any, we print out the results in a table, using the automatic row generation feature of Embperl and through the use of the $row global variable. If there were no matches, we report that as such. Finally, at the bottom of this page we provide a link back to the original script through the url function of the CGI.pm module.
One aspect of Embperl illustrated in this example is that when printing out raw HTML tags present in some variable $string through the [+ $string +] syntax, the tags themselves must be escaped. This is done explicitly in this example, although Embperl has the capability to do this automatically when certain options are set.
Screenshots of this application in action, which would be called as http://localhost/embperl/object/phone.html are similar to those of the corresponding Mason example, so will not be repeated here.
As was done with Mason, these examples are meant just to show the basic structure of Embperl. For more complex examples, again including some on interacting with databases and on handling form data and sessions (which requires the Apache::Session module), we refer to the web site at http://perl.apache.org/embperl/ and also to the examples contained within the source distribution. Also, if a lot of work is to be done with databases, we may want to look at the DBIx::RecordSet module, which gives a common interface to querying databases of various types, which is particularly suitable in a web environment. DBIx::RecordSet is written by the same author as Embperl and so the two modules work very nicely together.
‘Apache::ASP’
Apache::ASPis an implementation of Active Server Pages (see Chapter 9 for more on ASP) for the Apache web server using Perl as the scripting engine – for more details, see the web site at http://www.apache-asp.org/. After installation of the module, directives such as the following samples are inserted into Apache'shttpd.conffile:
PerlModule Apache::ASP
Alias /asp/ "/home/www/asp/"
<Location /asp>
SetHandler perl-script
PerlHandler Apache::ASP
PerSetVar Global /tmp
PerlSetVar CookiePath /
</Location> This assumes a mod_perl-enabled server. Any file placed in the /asp directory will be parsed by the Apache::ASP Apache handler.
As with Mason and Embperl, we give the simple example of printing out the values of the various environment variables:
<!--#include file=header.inc-->
<H3>Environment Variables</H3>
<CENTER>
<TABLE BORDER=1>
<TR><TH COLSPAN=2 ALIGN="left">Environment Variables</th></tr>
<% @colors = ("#FFFFFF", "#CCCCCC");
$x = 0;
sub _color{
return $x++ % 2 ? $colors[0] : colors[1];
}%>
<% for(sort keys %{$Request->ServerVariables()}) {
next unless /HTTP|SERVER|REQUEST/; %>
<TR BGCOLOR=<%=_color()%>>
<TD><TT><%=$_%></TT> </TD>
<TD><TT><%=$Request->ServerVariables($_)%></TT></TD>
</TR>
<% } %>
</TABLE>< /CENTER>
<!--#include file=footer.inc--> The invoked file, header.inc, is:
<%
$title = 'My Apache::ASP demo'; %> <HTML>
<HEAD>
<TITLE><%=$title%></TITLE><
/HEAD>
<BODY BGCOLOR="#ffffff" link="#ff5599" vlink="#993399">
<BR />The footer.inc file is given by:
<P>
Comments to
<A HREF="mailto:me@my.address.com">me</a>
are welcome.
</BODY>
</HTML> In Apache::ASP, Perl code is enclosed within <%...%> blocks. Variables to be printed out use the <%=$variable_name %> syntax. The environment variables themselves are contained within $Request->ServerVariables – note that we restrict the variables to match the regular expression /HTTP|SERVER|REQUEST/. If the file above is called environ3.html, a screenshot of the result of calling http://localhost/asp/environ3.html appears below:
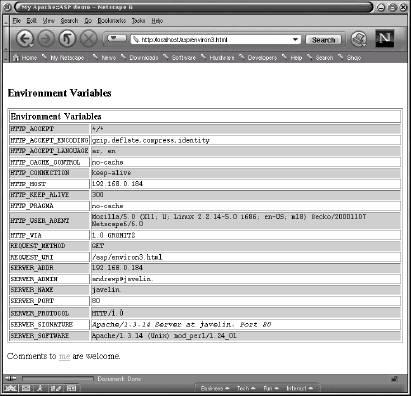
In the above example, $Request->ServerVariables was used to access the server environment variables. As the syntax indicates, $Request is an object and ServerVariables is a method available for that object. Apache::ASP supports a number of such (global) objects; the current ones available are:
$Session– user session state$Response– output to browser$Request– input from browser$Application– application state$Server– general support methods
There are many methods available for each of these objects – consult the documentation for a full description.
A Third Longer Example
As another example of using Apache::ASP, we again illustrate the use of the telephone book lookup form. As before, the data is assumed to be in /usr/local/data/phone.txt, with one entry per line containing the name and phone number of a person, separated by the # symbol. We will split this application across the usual four files – a master file, phone.html, the form itself, form.html, a lookup script, which gathers the data, lookup.html, and a script to print out the results, print_it.html. All files are to be placed in the directory specified by the /asp location in httpd.conf. We will also illustrate the use of cookies in this example for saving session data across invocations of the script.
The master file, phone.html, consists of:
#!/usr/bin/perl asp
<!--#include file=header.inc-->
<H3>Phone book example</H3>
<% use CGI qw(:all);
my $name = $Request->Form('name') || '';
if (! $name ) {
$Response->Include("form.html");
}
else {
$Response->Cookies('name' => $name);
$Response->Include("lookup.html", $name);
}
%>
<!--#include file=footer.inc--> We begin here by including the header.inc file (as in the previous example), and then pull in the CGI.pm module. We then check, through the use of $Request->Form('name'), if a value has been entered for the name parameter. If it hasn’t, we print out the form contained in the include file form.html. If a value has been entered, we set a cookie via $Response->Cookies('name' => $name) to save this value across sessions, and include the file lookup.html, which will query the database and print out the results. Note how we pass to this file the variable $name through the $Response->Include("lookup.html", $name) call. Finally we include the footer footer.inc. The file form.html used to print out the form by which the user enters the query is given by:
<%=start_form %>
<TABLE><TR>
<TD>Please enter the name:</TD>
<TD>
<%
print textfield(-name => 'name', size => 30,
-value => $Request->Cookies('name'));
%>
</TD>
</TR><TR>
<TD COLSPAN=2><%=submit(-value => 'Search!') %> </TD>
</TR></TABLE>
<%=end_form %> This, and later files, uses the methods of the CGI.pm module to print out various HTML tags. Note the use of $Request->Cookies('name')) to retrieve the value of name in the cookie (if it has been set) and use this value as the default for the textfield box in which the user enters the query.
When the user enters a value and submits the data, the file lookup.html will be called:
<%
my $name = shift;
my %match;
open (PHONE, "/usr/local/data/phone.txt")
or die "Cannot open phone.txt: $!";
while (<PHONE>) {
my @a = split /#/, $_;
next unless $a[0] =~ /$name/;
$match{$a[0]} = $a[1];
}
close (PHONE);
$Response->Include("print_it.html", (%match, $name));
%> The script first captures the $name variable passed to it in the master file. It then opens up the database file and cycles through the entries, saving those that match the search criteria in the hash %match. After the results are obtained, the database file is closed and a file, print_it.html, is included that will print out the results (note that a reference to the %match hash and the original query term $name are passed to this file through the $Response->Include(“print_it.html”, (%match, $name)) call). The print_it.html file is as follows:
<%
my ($match, $name) = @_;
my @names = sort keys %$match;
my $num = @names;
if ($num > 0) {
printf("<B>%d</B> match%s for "<B>%s</B>"
%s found:",
$num, ($num > 1 ? 'es' : ''), $name, ($num == 1 ? 'was'
: 'were') );
%>
<TABLE WIDTH="40%">
<TR><TH ALIGN="LEFT">Name</TH>
<TH ALIGN="LEFT">Number<TH></TR>
<TR><TD COLSPAN=2><HR></TR>
<%
foreach (@names) {
%>
<TR>
<TD ALIGN="LEFT"><%=$_%></TD>
<TD ALIGN="LEFT"><%=$match->{$_}%></TD>
</TR>
<% } %>
<TR><TD COLSPAN=2><HR></TR>
</TABLE>
<% }
else {
%>
Sorry – nothing matched "<B><%=$name%></B>".
<% }
%>
Try <A HREF="<%=url%>">another search</A>. In this file we first capture the variables passed into it from lookup.html. We then set $num equal to the number of successful matches obtained. If there were any, we print out the results in a table, or otherwise we report that no successful matches were obtained. Finally, at the bottom of this page we provide a link back to the original script through the url function of the CGI.pm module.
Screenshots of this application, called through http://localhost/asp/phone.html are similar to the previous ones, so will not be repeated here.
As was done with Mason and Embperl, these examples are meant just to show the basic usage of Apache::ASP. For more complex examples, again including some of interacting with databases and of handling form data and sessions, refer to the web site at http://www.apache-asp.org/ and also to the examples contained within the source distribution. Also, in the next chapter we look at how to embed Perlscript into Active Server Pages on an NT-based machine. Many of the methods applied there will be relevant to Apache::ASP also.
Summary
Although the examples used in this chapter were relatively short, their modularization illustrates some fundamental advantages present in this approach to constructing web pages. For example, for the phone book lookup program, in order to change the appearance of the printed results, only the print_it.html file needs to be modified. Or, if at some later time one wished to use a database rather than a text file (for example, MySQL), then only the file lookup.html need be changed to query the database and return the results.
As a short summary, we have covered various ways of embedding Perl into web pages. We have looked at templates, and used as
This article is an excerpt from the book Professional Perl Development from WROX Press. See Kevin Yank’s review here.
The exponential growth of the web in recent years has led to a number of conflicting demands on a site’s development team. On the one hand, users expect more than simple static content – they demand interactivity through forms, search facilities, customization of pages, and so on. At the same time, however, users anticipate such things as an aesthetically pleasing layout, easy navigation, and a similar look and feel among related pages. These demands in fact underline a fundamental direction that the Web is heading in – a separation of content from presentation. This separation in principle can make development of a site easier; first handle the generation of dynamic content, and then address how the results are to be presented. Ultimately however, one has to make an interface between the two – how to input the dynamic data into an HTML page.
In many cases, such as a search facility that looks up a query in some database, this interface can be handled through CGI scripts. Of course, Perl, and in particular the CGI.pm module (see Chapter 1), is justifiably famous for this. So much so that many bookstores, web sites, and news group posters consider Perl and CGI programming to be synonymous (much to the chagrin of, among others, regular posters to comp.lang.perl.misc). However, for more complicated applications and/or for large numbers of pages, an approach based on CGI scripts is not always satisfactory for a number of reasons:
- It does not always scale well.
- It can place large demands on the server.
- It can be difficult to manage for large sites.
A primary reason for these shortcomings is that the separation of content and presentation is not always so clean in a CGI script. Indeed, often it is just one script that generates both the content and the HTML tags, which makes it difficult to change the presentation or the content individually. There are, however, a number of different classes of solutions available within Perl that were developed to address this problem:
- HTML::Template
- Template
- HTML::Mason
- HTML::Embperl
- Apache::ASP
These approaches will be the main subject of this chapter. All of these modules are available on CPAN, and for UNIX can be installed in the usual ways. In a Win32 environment we may need an expensive C compiler to build and install them (particularly Visual C++ if we would also like to use them with mod_perl, described in Chapter 2). If we don’t have VC++, pre-built binaries of these modules are available through links listed at http://perl.apache.org/, including ppm (Perl Package Manager) files for Win32 ActivePerl.
Of course, constructing web pages can be handled purely from a CGI/mod_perl approach without the use of modules, such as those that will be described here for embedding Perl in a web page. The advantages of using these modules is that they are designed specifically for a web environment, and so have many optimal constructions and shortcuts built in that have been found very useful in this context. Also, many users have tested these modules extensively in this environment. Once we learn the syntax of a particular module, we are able to write components that are easily maintainable, reusable, and scalable and this has distinct advantages.
Templates
The philosophy of a template file is to make up a template describing the basic HTML layout that we wish to use. Within this file there are special indicators, which will be filled in dynamically from some script. There are a number of Perl modules available that can be used for this purpose, and like the question of ‘Which editor should I use?’, deciding which is best is often a matter of personal taste. Here we describe two basic modules to give a flavor for how they are used. For additional details and a list of further such modules, we ought to browse CPAN – a convenient way to do this is through a CPAN search engine such as:
- http://search.cpan.org
- http://www.perldoc.com
- http://theoryx5.uwinnipeg.ca/mod_perl/cpan-search
‘HTML::Template’
A basic template with this module has the following form:
<HTML>
<HEAD><TITLE>Test Template</TITLE></HEAD>
<BODY>
<TMPL_INCLUDE NAME="header.tmpl">
Please contact the person listed below: <BR>
<A HREF="mailto:<TMPL_VAR NAME=email>">
<TMPL_VAR NAME=person> </A> <TMPL_INCLUDE NAME="footer.tmpl">Common headers and footers can be inserted with the <TMPL_INCLUDE NAME=”file”> syntax, as indicated. If we call this template greeting1.tmpl, then we can generate a dynamic page using it as in the following script:
#!/usr/bin/perl
# htmltemplate.pl
use warnings;
use strict;
use HTML::Template;
my $template = HTML::Template->new(filename => 'greeting1.tmpl');
$template->param('email', 'bill@nowhere.com');
$template->param('person', 'William');
print "Content-Type: text/htmlnn";
print $template->output; The output method is then used to generate the filled-in template page.
‘Template’
In the Template module (part of the Template-Toolkit package), the basic HTML template has variable placeholders indicated by the [% ... %] syntax, as in the following example:
[% INCLUDE header %]
Please contact the person listed below: <BR>
<a href="mailto:[% email %]">[% person %]</a>
[% INCLUDE footer %]Note the use of INCLUDE to include common headers and footers. If we call this template greeting2.html, then we can generate a dynamic page using this template as in the following script:
#!/usr/bin/perl
# template.pl
use warnings;
use strict;
use Template;
$| = 1;
print "Content-type: text/htmlnn";
my $file = 'greeting2.html';
my $vars = {
'email' => 'bill@nowhere.com',
'person' => 'William',
};
my $template = Template->new({
INCLUDE_PATH => '/home/me/templates:/home/me/lib',
});
$template->process($file, $vars) || die $template->error();Note the use of INCLUDE_PATH when creating the Template object to specify which directories to search for the template files. The process method is the basic workhorse of the module – it takes the template specified by $file, and applies the variable substitutions in this file specified by $vars.
These modules, and others, support more than just simple variable substitutions. For example, in the Template module, simple loop constructions and conditionals can be incorporated. If in the script we set the following:
$vars = {
'people' => [ 'Tom', 'Dick', 'Larry', 'Mary' ],
}; and in the template file:
[% FOREACH person = people %]
Hello [% person %]
[% END %] the script will iterate over the members of the people array reference and print out the corresponding value (individual members can be accessed in the template as, for example, [% people.1 %], which will correspond to Dick in the above example). In addition to insertion, replacement, loops, and conditionals, the Template module has directives for dynamically invoking other template files, a macro capability, exception raising and handling, and some invocation of Perl code. For example, the processing of form data can be done within the Template module through the CGI.pm module simply by including the following in the template file:
[% USE CGI %] The methods of the CGI.pm module can then be accessed through syntax such as:
[% CGI.header %]
[% CGI.param('parameter') %] These template modules can be used in a mod_perl-enabled server to speed up generation of the pages. One of the advantages of these approaches is that a relatively clean separation between content and display is obtained. Due to the relative simplicity of the template indicators, it is reasonable to have, for example, a web designer work on a template file and a programmer work on the data generation. However, for more complex situations, a greater degree of programming constructions may be required and these will be described in the next sections.
‘HTML::Mason’
This module, which is described in more detail at http://www.masonhq.com/, uses the idea of components, which are mixtures of HTML, Perl code, and Mason commands. A top-level component represents an entire page, while smaller components can be used to generate snippets of HTML to be used in a larger component. Such a design can simplify site management significantly, as changing a shared sub-component can instantaneously change a large number of pages that use this component.
Embedding Perl into Web Pages 355 After installing the module, directives such as those in the following sample are placed in Apache’s httpd.conf file:
PerlRequire /path/to/Mason/handler.pl # bring in the handler.pl file
Alias /mason/ "/home/www/mason/" # create a special directory for
# Mason files
<Location /mason>
SetHandler perl-script
PerlHandler HTML::Mason
</Location> This assumes that we have a mod_perl-enabled Web server. The handler.pl file is used to start Mason and to define a routine to handle the requests passed to it under the Location directive. The following is a sample handler.pl file:
#!/usr/bin/perl
# handler.pl
package HTML::Mason;
use HTML::Mason;
use HTML::Mason::ApacheHandler;
use strict;
use warnings;
# list of modules that we want to use from components (see Admin
# manual for details)
{
package HTML::Mason::Commands;
use DBI;
use CGI qw(:all);
use CGI::Cookie;
use Fcntl;
use MLDBM;
use LWP;
}
# create Mason objects
my $parser = new HTML::Mason::Parser;
my $interp = new HTML::Mason::Interp (parser=>$parser,
comp_root => '/home/www/mason',
data_dir => '/usr/local/apache/mason');
my $ah = new HTML::Mason::ApacheHandler (interp => $interp);
chown (scalar(getpwnam "nobody"), scalar(getgrnam "nobody"),
$interp->files_written);
sub handler
{
my ($r) = @_;
my $status = $ah->handle_request($r);
return $status;
}
1; The handler.pl file typically creates three objects:
- A parser – transforms components into Perl subroutines
- An interpreter – executes these subroutines
- A handler – routes mod_perl to Mason
The comp_root directory is a virtual root for Mason’s component file system, like the server’s DocumentRoot directive (they may be the same). The data_dir directory will be used by Mason to generate various data files. Note the convenient ability in this file to load modules to be used in other components.
We illustrate the use of Mason with a simple example, which prints out the values of the environment variables:
<%perl>
my $col1 = "Key";
my $col2 = "Value";
</%perl>
<h2><% $headline %></h2>
<table width=450>
<tr <& .bgcolor &>>
<th align=left><% $col1 %></th>
<th align=left><% $col2 %></th>
</tr>
% foreach my $key (sort keys %ENV){
<tr <& .bgcolor &>>
<td valign=top><b><& .font, val=>$key &></b></td>
<td><& .font, val=>$ENV{$key} &></td>
</tr> % }
</table>
<%init>
my $headline = "The Environment variables:";
</%init>
<%def .font>
<font size=1 face='Verdana, sans-serif'> <% $val %> </font>
<%args>
$val=>""
</%args>
</%def>
<%def .bgcolor>
% my $color= $x++%2?$colors[0]:$colors[1];
bgcolor="#<% $color %>"
</%def>
<%once>
my $x = 0;
my @colors = ('FFFFFF', 'CCCCCC');
</%once>If we place this file, say environ1.html, in the directory specified by the /mason location in httpd.conf, and call it with http://localhost/mason/environ1.html, the following results are obtained:
The various sections of the file are described below:
- The
<%perl>...</%perl>section is used for a block of Perl code. In it we declare the variables$col1and$col2. - After this, we give the level 2 heading using the variable $headline, which is initialized in the
<%init>...</%init>block (this is executed as soon as the component is loaded). Note the use of<%...%>to echo the value of $headline within a line of HTML code. - Next we set up the table used to print out the values of the environment variables. Headings for this table use the component
.bgcolor(note the convention of using a leading period in defining component names). Components are called with the syntax<& component_name, [variables] &>; this particular component is defined in a<%def>...</%def>section. Note the use of a leading % to denote a single line of Perl code. - We next set up a loop to print out all available environment variables. As well as the .bgcolor component used previously, this block uses the .font component. This particular component also uses a
<%perl>...</%perl>section to handle passing of arguments from the<& component_name, [variables] &>call. - Finally, we use a
<%once>...</%once>section to set the variables used in determining the background color for the table row.
If we look carefully at the screenshot we will notice that the page has a title and a line, which we didn’t set explicitly. What happened is that we have also defined a special component file called autohandler, which gets called every time a top-level component is invoked and which is interpreted before the called components are interpreted. The component used in this particular example, which should also be placed in the directory specified by the /mason location in httpd.conf, is listed below:
<HTML>
<HEAD> <TITLE>Embedding Perl into Web Pages with HTML::Mason</TITLE>
</HEAD>
<BODY BGCOLOR="#FFFFFF">
<B>Mason Example:</B>
<% $m->call_next %>
</BODY>
</HTML> The <% $m->call_next %> line passes control to the next component (in this case, the original page called). These handlers are directory based, meaning that it is very easy to change the layout of a large number of pages just by changing this particular component.
A Longer Example
As a more involved example of using HTML::Mason, we illustrate the use of a telephone book lookup form. In this example, the data is assumed to be in a file /usr/local/data/phone.txt, with one entry per line containing the name and phone number of a person, separated by the # symbol. This is an example of what it should look like:
Andrew Logan#377-0971 Matt Jones#598-6788 We split this application across four files – a master file (called phone.html), a form through which a user enters a query (called form), a lookup script that gathers the data from the database (called lookup.html), and finally a script to print out the results (called print_it). We will also have a header file, header, and a footer file, footer, called though the autohandler template file. Also in this example, we illustrate the use of cookies in saving session data across invocations of the script. All files are to be placed in the directory specified by the /mason location in httpd.conf.
Using the same Apache configuration as before, we first give the autohandler template file:
% my $title = 'My HTML::Mason demo';
<& header, title => $title &>
<H3>Phone book example</H3>
<% $m->call_next %>
<& footer &> The header file, called with a parameter title through the syntax <& header, title => $title &>, is:
<HTML>
<HEAD><TITLE><% $title %></ TITLE ></HEAD>
<body bgcolor="#ffffff" link="#ff5599" vlink="#993399">
<BR>
<%ARGS>
$title => undef
</%ARGS> And the footer file is:
<P>
Comments to
<A HREF="mailto:me@my.address.com">me</A>
are welcome.
</BODY>
</HTML> Note the use of the <%ARGS>...</%ARGS> construction, which is used to define arguments to be passed into the file. The master file by which the script is called, phone.html, contains:
% my $name = param('name');
% if (! $name) {
<& form &>
% }
% else {
% $r->header_out('Set-Cookie', "name = $name");
<& lookup.html, name => $name &>
% } We begin here by checking, via the param method of the CGI.pm module (pulled in through handler.pl), if a value has been entered for the name parameter. If it hasn’t, we print out the form contained in the file form. If a value has been entered, we set a cookie via the mod_perl-specific call $r->header_out('Set-Cookie', "name = $name") to save this value across sessions, and then call lookup, which will query the database and print out the results. Note that we pass to this file the variable $name.
The file form used to print out the form by which the user enters the query contains:
% my $val = cookie(-name => 'name');
<FORM>
<TABLE><TR>
<TD>Please enter the name:</TD>
<TD>
<INPUT TYPE="text" NAME="name" SIZE=30 VALUE="<% $val %>">
</TD>
</TR><TR>
<TD COLSPAN=2>
<INPUT TYPE="submit" VALUE="Search!"> </TD></TR></TABLE>
</FORM> This uses the cookie method of the CGI.pm module to retrieve the value of the cookie associated with the name parameter, if it is present. This value is used as the default for the textfield box in which the user enters the query.
When the user enters a value and submits the data, the file lookup.html will be called. This file is given by:
<%perl>
my %match;
open (PHONE, "/usr/local/data/phone.txt") or
die "Cannot open phone.txt: $!";
while (<PHONE>) {
my @a = split /#/, $_;
next unless $a[0] =~ /$name/;
$match{$a[0]} = $a[1];
}
close (PHONE);
</%perl>
<& print_it, match => %match, name => $name &>
<%ARGS>
$name => undef
</%ARGS> In this file, we first open up the file and cycle through the entries, saving those entries that match the search criteria in the hash %match. Note that, as with any CGI script, some form of taint checking should be done on any user-supplied input – see perldoc perlsec for a discussion. After the results are obtained, the file is closed and print_it is called, which will print out the results (note that a reference to the %match hash and the original query term $name are passed to this file). The print_it file is as follows:
<%perl>
my @names = sort keys %$match;
my $num = @names;
if ($num > 0) {
my $string = sprintf(
"<B>%d</B> match%s for "<B>%s</B>" %s found:",
$num, ($num > 1 ? 'es' : ''), $name,
($num == 1 ? 'was' : 'were') );
</%perl>
<% $string %>
<TABLE WIDTH="40%">
<TR><TD COLSPAN=2><HR></TD></TR>
<TR><TH ALIGN="LEFT">Name</TH>
<TH ALIGN="LEFT">Number<TH></TR> % foreach (@names) {
<TR>
<TD ALIGN="LEFT"><% $_ %></TD>
<TD ALIGN="LEFT"><% $match->{$_} %></TD>
</TR>
% }
<TR><TD COLSPAN=2><HR></TD></TR>
</TABLE>
% }
% else {
Sorry nothing matched "<B><% $name %></B>".
% }
% my $url = url;
Try <A HREF="<% $url %>">another search</A>.
<%ARGS>
$match => undef
$name => undef
</%ARGS> In this file we first construct an array @names from the passed %match hash reference, which contains the names of the successful matches. We also set a variable $num equal to the number of successful matches obtained. If there were any, we print out the results in a table. If there were no matches we report that as such. Finally, at the bottom of this page we provide a link back to the original script through the url function of the CGI.pm module.
Some screenshots of this application in action appear below. When the address http://localhost/mason/phone.html is first requested, the basic form is presented through which the user enters a query:
Upon entering a query (say M) and submitting the form, the results are then presented:
If the user selects the another search link, the original query form is presented, but with the textfield filled in via the cookie, with the default value from the original query.
These examples just show the basic structure of Mason. For more complex examples, we can refer to the Mason web site at http://www.masonhq.com/ and also to the examples contained within the source distribution.
‘HTML::Embperl’
HTML::Embperl is another approach to being able to embed Perl code in HTML pages. For more details than are provided here, see the documentation at http://perl.apache.org/embperl/. After installation of the module, directives such as the following samples are to be placed into Apache’s httpd.conf file:
PerlModule HTML::Embperl
Alias /embperl/ "/home/www/embperl/"
<Location /embperl>
SetHandler perl-script
PerlHandler HTML::Embperl
Options ExecCGI FollowSymLinks
</Location>
PerlModule HTML::EmbperlObject
<Location /embperl/object>
PerlSetEnv EMBPERL_OBJECT_BASE base.html
PerlSetEnv EMBPERL_FILESMATCH ".htm.?|.epl$"
PerlSetEnv EMBPERL_OPTIONS 16
SetHandler perl-script
PerlHandler HTML::EmbperlObject
Options ExecCGI
</Location> This assumes a mod_perl-enabled server. Any file placed in the /embperl directory will be parsed by the HTML::Embperl Apache handler first. Any file that matches the rule stated by the EMBPERL_FILESMATCH environment variable and placed in the /embperl/object directory will be delivered through the HTML::EmbperlObject Apache handler.
To give a flavor of how Embperl is used, we give the simple example of printing out the values of the various environment variables:
[!
$x = 0;
@colors = ("#FFFFFF", "#CCCCCC");
sub _color{
return $x++ % 2 ? $colors[0] : $colors[1];
}
!]
<br>
<TABLE width=450>
[-
@k = sort keys %ENV;
@headlines = ('Key', 'Value');
-]
<tr bgcolor="[+ &_color() +]">
<th align=left>[+ $headlines[$col] +]</th>
</tr>
<TR bgcolor="[+ &_color() +]">
<TD><font size=1 face="Verdana, sans-serif">
[+ $k[$row] +] </font></TD>
<TD><font size=1 face="Verdana, sans-serif">
[+ $ENV{$k[$row]} +] </font></TD>
</TR>
</TABLE> If this file, say environ2.html, is placed in the directory specified by the /embperl location in httpd.conf, the result of calling http://localhost/embperl/environ2.html is:
The meaning of the various lines of the Embperl page are described below:
- The syntax
[!...!]first encountered is used to compile (once) a block of Perl code. The first such block is used to set up the colors used in the table rows and to define a Perl subroutine that will determine the particular color to use. - Next is the
[-...-]syntax and this is used to compile a block of Perl code. This particular one establishes arrays to be used to set the table headings and the value of the various environment variables. - The color subroutine is called through the
&_colorsyntax. This is wrapped within a[+...+]block, which will print out the returned value. - A very powerful feature of
Embperlillustrated in this example is automatic looping over of variables in a table context. In the first illustration, which sets the table headings, as many<TH>tags will be generated as needed, based on the input from the@headlinesarray. The iteration is done with the special global variable $col as the iterator, which holds the number associated with the current column. - This same feature of automatic looping is also illustrated for the table rows, where in this case the required number of rows is automatically generated from input from the %ENV hash. Here, the special global variable
$rowis used as the iterator, which holds the number associated with the current row.
The templating capabilities of Embperl are based on the use of the HTML::EmbperlObject Apache handler, which functions in a manner similar to HTML::Mason‘s autohandler. To illustrate this, we place the above file, say environ2.html, in the /embperl/object directory specified in httpd.conf. We then construct a file, in the same directory, specified by EMBPERL_OBJECT_BASE (in our example, base.html), which will hold the master template that will be applied to any requested page. A sample base.html appears below:
<HTML>
<HEAD>
<title>Embedding Perl into Web Pages with HTML::Embperl</title>
</HEAD>
<BODY BGCOLOR="#FFFFFF">
[- Execute ('header.html') -]
[- Execute ('*') -]
[- Execute ('footer.html') -]
</BODY>
</HTML> Here we have included two other files, header.html and footer.html, defining an included header and footer. These are to be placed in the same directory as base.html. An example header.html is:
<H2>HTML::Embperl - EmbperlObject example</H2> An example footer.html is:
<BR>
<HR size=1 noshade width=450 align=left>
Wrox Press, 2000<BR>
[+ localtime +]Embedding Perl into Web Pages 365 Finally, requesting the http://localhost/embperl/object/environ2.html will generate the following results. The screenshots show the header and footer files implemented:
A Longer Example Revisited
As a more involved example of using HTML::Embperl, we illustrate the use of the telephone book lookup form. As before, the data is assumed to be in the file /usr/local/data/phone.txt, with one entry per line containing the name and phone number of a person, separated by the # symbol. We split this application across four files – a master file, phone.html, the query form, form.html, a lookup script, which gathers the data from the database, lookup.html, and a script to print out the results, print_it.html. In this example we also illustrate the use of cookies in saving session data across invocations of the script.
Within the <Location> directive specifying /embperl/object we also added:
PerlSetEnv EMBPERL_OPTIONS 16 This directs Embperl not to pre-process the source for Perl expressions and is useful if we use a text editor for writing code. We should not set this if we use a WYSIWYG editor, which inserts unwanted HTML tags and escapes special characters automatically (for example, > to >). See the HTML::Embperl documentation for further details on this and other options.
All files, using the previous Apache configuration, are to be placed in the directory specified by the /embperl/object location. The base file base.html is given by:
[- Execute 'header.html' -]
<H3>Phone book example</H3>
[- Execute ('*') -]
[- Execute 'footer.html' -]The header.html is:
[-
$title = 'My HTML::Embperl demo';
-]
<HTML>
<HEAD><TITLE>[+ $title +]</TITLE></HEAD>
<body bgcolor="#ffffff" link="#ff5599" vlink="#993399">
<BR> And, footer.html is:
<P>
Comments to
<A HREF="mailto:me@my.address.com">me</a>
are welcome.
</BODY>
</HTML> The master file by which the script is called, phone.html, consists of:
[$if ! $fdat{name} $]
[- Execute 'form.html' -]
[$else$]
[-
$http_headers_out{'Set-Cookie'} = "name=$fdat{name}";
Execute({inputfile => 'lookup.html', param => [$fdat{name}]});
-]
[$endif$]We begin here by checking the special %fdat hash (containing the form data, which Embperl automatically supplies) for a value having been entered for the name parameter. If it hasn’t, we print out the form contained in the include file form.html. If a value has been entered, we set a cookie via $http_headers_out{'Set-Cookie'}= "name=$fdat{name}" to save this value across sessions, and include a file lookup.html, which will query the database and print out the results. Note how we pass to this file the variable $name through the Execute({inputfile => 'lookup.html', param => [$fdat{name}]}) call. This example also illustrates how to set up if...else blocks within Embperl through the [$if$]...[$else$]...[$endif$] syntax (a similar syntax is available for while loops).
The file form.html used to print out the form by which the user enters the query is given by:
[- use CGI qw(cookie);
$val = cookie(-name => 'name');
-]
<FORM>
<TABLE><TR>
<TD>Please enter the name:</TD>
<TD>
<INPUT TYPE="text" NAME="name" SIZE=30 VALUE="[+$val+]">
</TD>
</TR><TR>
<TD COLSPAN=2>
<INPUT TYPE="submit" VALUE="Search!">
</TD></TR></TABLE>
</FORM> This uses the cookie method of the CGI.pm module to retrieve the value of the cookie associated with the name parameter, if it is present. This value is used as the default for the textfield box in which the user enters the query.
When the user enters a value and submits the data, the file lookup.html will be called. This file is shown below:
[-
$name = $param[0];
open (PHONE, "/use/local/data/phone.txt")
or die "Cannot open phone.txt: $!";
while (<PHONE>) {
my @a = split /#/, $_;
next unless $a[0] =~ /$name/;
$match{$a[0]} = $a[1];
}
close (PHONE);
Execute({inputfile => "print_it.html", param => [%match, $name]});
-] First it captures the $name variable passed to it in the master file via the @param array. It then opens up the database file and cycles through the entries, saving those entries that match the search criteria in the hash %match. After the results are obtained, the file is closed and a file print_it.html is included, which will print out the results (note that a reference to the %match hash containing the results and the original query term $name are passed to this file through the Execute call). The print_it.html file is as follows:
[-
$match = $param[0];
$name = $param[1];
@names = sort keys %$match;
@nums = map {$match->{$_}} @names;
$num = @names;
-]
[$if ($num > 0) $]
[-
$string = sprintf(
"\<B\>%d\</B\> match%s for \"\<B\>%s\</B\
>\" %s found:",
$num, ($num > 1 ? 'es' : ''), $name, ($num == 1 ? 'was'
: 'were') );
-]
[+ $string +]
<HR>
<TABLE WIDTH="40%">
<TR><TH ALIGN="LEFT">Name</TH>
<TH ALIGN="LEFT">Number<TH></TR>
<TR>
<TD ALIGN="LEFT">[+ $names[$row] +]</TD>
<TD ALIGN="LEFT">[+ $nums[$row] +]</TD>
</TR>
</TABLE>
<HR>
[$else$]
Sorry - nothing matched "<B>[+ $name +]</B>".
[$endif$]
[- use CGI qw(url);
$url = url;
-]
Try <A HREF="[+ $url +]">another search</A>. In this file we first capture the variables passed into it from lookup.html via the @param array. For later use we construct two arrays, @names and @nums, from the passed %match hash reference. These arrays contain respectively, the names and the numbers of the successful matches. We also set a variable $num equal to the number of successful matches obtained. If there were any, we print out the results in a table, using the automatic row generation feature of Embperl and through the use of the $row global variable. If there were no matches, we report that as such. Finally, at the bottom of this page we provide a link back to the original script through the url function of the CGI.pm module.
One aspect of Embperl illustrated in this example is that when printing out raw HTML tags present in some variable $string through the [+ $string +] syntax, the tags themselves must be escaped. This is done explicitly in this example, although Embperl has the capability to do this automatically when certain options are set.
Screenshots of this application in action, which would be called as http://localhost/embperl/object/phone.html are similar to those of the corresponding Mason example, so will not be repeated here.
As was done with Mason, these examples are meant just to show the basic structure of Embperl. For more complex examples, again including some on interacting with databases and on handling form data and sessions (which requires the Apache::Session module), we refer to the web site at http://perl.apache.org/embperl/ and also to the examples contained within the source distribution. Also, if a lot of work is to be done with databases, we may want to look at the DBIx::RecordSet module, which gives a common interface to querying databases of various types, which is particularly suitable in a web environment. DBIx::RecordSet is written by the same author as Embperl and so the two modules work very nicely together.
‘Apache::ASP’
Apache::ASPis an implementation of Active Server Pages (see Chapter 9 for more on ASP) for the Apache web server using Perl as the scripting engine – for more details, see the web site at http://www.apache-asp.org/. After installation of the module, directives such as the following samples are inserted into Apache'shttpd.conffile:
PerlModule Apache::ASP
Alias /asp/ "/home/www/asp/"
<Location /asp>
SetHandler perl-script
PerlHandler Apache::ASP
PerSetVar Global /tmp
PerlSetVar CookiePath /
</Location> This assumes a mod_perl-enabled server. Any file placed in the /asp directory will be parsed by the Apache::ASP Apache handler.
As with Mason and Embperl, we give the simple example of printing out the values of the various environment variables:
<!--#include file=header.inc-->
<H3>Environment Variables</H3>
<CENTER>
<TABLE BORDER=1>
<TR><TH COLSPAN=2 ALIGN="left">Environment Variables</th></tr>
<% @colors = ("#FFFFFF", "#CCCCCC");
$x = 0;
sub _color{
return $x++ % 2 ? $colors[0] : colors[1];
}%>
<% for(sort keys %{$Request->ServerVariables()}) {
next unless /HTTP|SERVER|REQUEST/; %>
<TR BGCOLOR=<%=_color()%>>
<TD><TT><%=$_%></TT> </TD>
<TD><TT><%=$Request->ServerVariables($_)%></TT></TD>
</TR>
<% } %>
</TABLE>< /CENTER>
<!--#include file=footer.inc--> The invoked file, header.inc, is:
<%
$title = 'My Apache::ASP demo'; %> <HTML>
<HEAD>
<TITLE><%=$title%></TITLE><
/HEAD>
<BODY BGCOLOR="#ffffff" link="#ff5599" vlink="#993399">
<BR />The footer.inc file is given by:
<P>
Comments to
<A HREF="mailto:me@my.address.com">me</a>
are welcome.
</BODY>
</HTML> In Apache::ASP, Perl code is enclosed within <%...%> blocks. Variables to be printed out use the <%=$variable_name %> syntax. The environment variables themselves are contained within $Request->ServerVariables – note that we restrict the variables to match the regular expression /HTTP|SERVER|REQUEST/. If the file above is called environ3.html, a screenshot of the result of calling http://localhost/asp/environ3.html appears below:
In the above example, $Request->ServerVariables was used to access the server environment variables. As the syntax indicates, $Request is an object and ServerVariables is a method available for that object. Apache::ASP supports a number of such (global) objects; the current ones available are:
$Session– user session state$Response– output to browser$Request– input from browser$Application– application state$Server– general support methods
There are many methods available for each of these objects – consult the documentation for a full description.
A Third Longer Example
As another example of using Apache::ASP, we again illustrate the use of the telephone book lookup form. As before, the data is assumed to be in /usr/local/data/phone.txt, with one entry per line containing the name and phone number of a person, separated by the # symbol. We will split this application across the usual four files – a master file, phone.html, the form itself, form.html, a lookup script, which gathers the data, lookup.html, and a script to print out the results, print_it.html. All files are to be placed in the directory specified by the /asp location in httpd.conf. We will also illustrate the use of cookies in this example for saving session data across invocations of the script.
The master file, phone.html, consists of:
#!/usr/bin/perl asp
<!--#include file=header.inc-->
<H3>Phone book example</H3>
<% use CGI qw(:all);
my $name = $Request->Form('name') || '';
if (! $name ) {
$Response->Include("form.html");
}
else {
$Response->Cookies('name' => $name);
$Response->Include("lookup.html", $name);
}
%>
<!--#include file=footer.inc--> We begin here by including the header.inc file (as in the previous example), and then pull in the CGI.pm module. We then check, through the use of $Request->Form('name'), if a value has been entered for the name parameter. If it hasn’t, we print out the form contained in the include file form.html. If a value has been entered, we set a cookie via $Response->Cookies('name' => $name) to save this value across sessions, and include the file lookup.html, which will query the database and print out the results. Note how we pass to this file the variable $name through the $Response->Include("lookup.html", $name) call. Finally we include the footer footer.inc. The file form.html used to print out the form by which the user enters the query is given by:
<%=start_form %>
<TABLE><TR>
<TD>Please enter the name:</TD>
<TD>
<%
print textfield(-name => 'name', size => 30,
-value => $Request->Cookies('name'));
%>
</TD>
</TR><TR>
<TD COLSPAN=2><%=submit(-value => 'Search!') %> </TD>
</TR></TABLE>
<%=end_form %> This, and later files, uses the methods of the CGI.pm module to print out various HTML tags. Note the use of $Request->Cookies('name')) to retrieve the value of name in the cookie (if it has been set) and use this value as the default for the textfield box in which the user enters the query.
When the user enters a value and submits the data, the file lookup.html will be called:
<%
my $name = shift;
my %match;
open (PHONE, "/usr/local/data/phone.txt")
or die "Cannot open phone.txt: $!";
while (<PHONE>) {
my @a = split /#/, $_;
next unless $a[0] =~ /$name/;
$match{$a[0]} = $a[1];
}
close (PHONE);
$Response->Include("print_it.html", (%match, $name));
%> The script first captures the $name variable passed to it in the master file. It then opens up the database file and cycles through the entries, saving those that match the search criteria in the hash %match. After the results are obtained, the database file is closed and a file, print_it.html, is included that will print out the results (note that a reference to the %match hash and the original query term $name are passed to this file through the $Response->Include(“print_it.html”, (%match, $name)) call). The print_it.html file is as follows:
<%
my ($match, $name) = @_;
my @names = sort keys %$match;
my $num = @names;
if ($num > 0) {
printf("<B>%d</B> match%s for "<B>%s</B>"
%s found:",
$num, ($num > 1 ? 'es' : ''), $name, ($num == 1 ? 'was'
: 'were') );
%>
<TABLE WIDTH="40%">
<TR><TH ALIGN="LEFT">Name</TH>
<TH ALIGN="LEFT">Number<TH></TR>
<TR><TD COLSPAN=2><HR></TR>
<%
foreach (@names) {
%>
<TR>
<TD ALIGN="LEFT"><%=$_%></TD>
<TD ALIGN="LEFT"><%=$match->{$_}%></TD>
</TR>
<% } %>
<TR><TD COLSPAN=2><HR></TR>
</TABLE>
<% }
else {
%>
Sorry – nothing matched "<B><%=$name%></B>".
<% }
%>
Try <A HREF="<%=url%>">another search</A>. In this file we first capture the variables passed into it from lookup.html. We then set $num equal to the number of successful matches obtained. If there were any, we print out the results in a table, or otherwise we report that no successful matches were obtained. Finally, at the bottom of this page we provide a link back to the original script through the url function of the CGI.pm module.
Screenshots of this application, called through http://localhost/asp/phone.html are similar to the previous ones, so will not be repeated here.
As was done with Mason and Embperl, these examples are meant just to show the basic usage of Apache::ASP. For more complex examples, again including some of interacting with databases and of handling form data and sessions, refer to the web site at http://www.apache-asp.org/ and also to the examples contained within the source distribution. Also, in the next chapter we look at how to embed Perlscript into Active Server Pages on an NT-based machine. Many of the methods applied there will be relevant to Apache::ASP also.
Summary
Although the examples used in this chapter were relatively short, their modularization illustrates some fundamental advantages present in this approach to constructing web pages. For example, for the phone book lookup program, in order to change the appearance of the printed results, only the print_it.html file needs to be modified. Or, if at some later time one wished to use a database rather than a text file (for example, MySQL), then only the file lookup.html need be changed to query the database and return the results.
As a short summary, we have covered various ways of embedding Perl into web pages. We have looked at templates, and used two modules, HTML::Template and Template. We have also looked at two simple examples involving environment variables and a phone book lookup program using three modules: HTML::Mason, HTML::Embperl and Apache::ASP.
Like the question of the best editor, and indeed as is a general principle of Perl, the different modules have advantages in given situations, and which one to use is often a matter of personal taste, preference, and familiarity.
m “Superpaint.”In 1981, the design and concepts which gave birth to the Alto led to the development and production of the much more streamlined, and more usable Xerox Star – the first true GUI-driven PC. According to Bruce Horn, an ex-Xerox employee who wound up working for Apple, the software architecture for Smalltalk and the Star were much more sophisticated than the Mac or Windows equivalents. While the Apple machines incorporated much of Xerox’s brainstorms, many of the most innovative and sophisticated ideas never made it into the Apples, mostly due to Apple’s insistence on keeping costs down. The Star featured the first “compute two modules, HTML::Template and Template. We have also looked at two simple examples involving environment variables and a phone book lookup program using three modules: HTML::Mason, HTML::Embperl and Apache::ASP.
Like the question of the best editor, and indeed as is a general principle of Perl, the different modules have advantages in given situations, and which one to use is often a matter of personal taste, preference, and familiarity.
Frequently Asked Questions about Embedding Perl in Web Pages
What is Perl and why is it used in web development?
Perl is a high-level, general-purpose, interpreted, dynamic programming language. It was originally developed for text manipulation but now it is used for a wide range of tasks including system administration, web development, network programming, GUI development, and more. Perl is known for its flexibility and power, and it’s particularly good at processing text. It’s often used for CGI scripts, which are a common way to add interactivity to web pages.
How can I embed Perl in HTML?
Embedding Perl in HTML can be done using a variety of methods. One common method is to use the CGI.pm module, which allows you to create HTML forms and parse their contents. Another method is to use embedded Perl (ePerl), which allows you to embed Perl code directly into your HTML files. This can be useful for creating dynamic web pages.
What is the difference between Perl and other scripting languages like Python or Ruby?
Perl, Python, and Ruby are all powerful scripting languages, but they each have their own strengths and weaknesses. Perl is known for its flexibility and power, especially when it comes to text processing. Python is known for its simplicity and readability, making it a great choice for beginners. Ruby is known for its elegance and its strong support for object-oriented programming.
How can I execute Perl scripts on a web server?
To execute Perl scripts on a web server, you first need to ensure that the server is configured to handle Perl scripts. This usually involves setting the correct permissions on the script and placing it in the correct directory. Once this is done, you can execute the script by accessing its URL in a web browser.
What are the benefits of using Perl for web development?
Perl offers several benefits for web development. Its powerful text processing capabilities make it ideal for handling HTML, XML, and other markup languages. It also has strong support for regular expressions, which are often used in web development for pattern matching. Additionally, Perl’s flexibility allows it to easily integrate with other technologies used in web development, such as databases and web servers.
How can I learn Perl?
There are many resources available for learning Perl. The official Perl website offers a wealth of information, including tutorials and documentation. There are also many books and online courses available. One of the best ways to learn Perl is to start writing scripts and experimenting with the language.
What is CGI in Perl?
CGI stands for Common Gateway Interface. It’s a standard that allows web servers to interact with scripts or programs to create dynamic web pages. In Perl, the CGI.pm module provides a simple and convenient way to create CGI scripts.
How can I debug Perl scripts?
Perl provides several tools for debugging scripts. The Perl debugger is a powerful tool that allows you to step through your code, set breakpoints, and inspect variables. There are also several modules available on CPAN that can help with debugging, such as Devel::Trace and Devel::DProf.
What is CPAN in Perl?
CPAN stands for Comprehensive Perl Archive Network. It’s a repository of over 150,000 Perl modules written by programmers around the world. These modules provide solutions for a wide range of tasks, from web development to system administration.
How can I install Perl modules?
Perl modules can be installed using the CPAN module, which is included with Perl. To install a module, you simply need to run the command ‘install Module::Name’ from the CPAN shell. You can also use the cpanm tool, which provides a more streamlined interface for installing modules.
 Wrox Press
Wrox Press



